Video playback has different performance challenges at different scales, and mobile devices are a great place to see that in action. Nowhere is this more evident than in the iPhone/iPad lineup, where the same iOS 9.3 runs across several years worth of models with a huge variance in CPU speeds…
In ogv.js 1.1.2 I’ve got the threading using up to 3 threads at maximum utilization (iOS devices so far have only 2 cores): main thread, video decode thread, and audio decode thread. Handling of the decoded frames or audio packets is serialized through the main thread, where the player logic drives the demuxer, audio output, and frame blitting.
On the latest iPad Pro 9.7″, advertising “desktop-class performance”, I can play back the Blender sci-fi short Tears of Steel comfortably at 1080p24 in Ogg Theora:
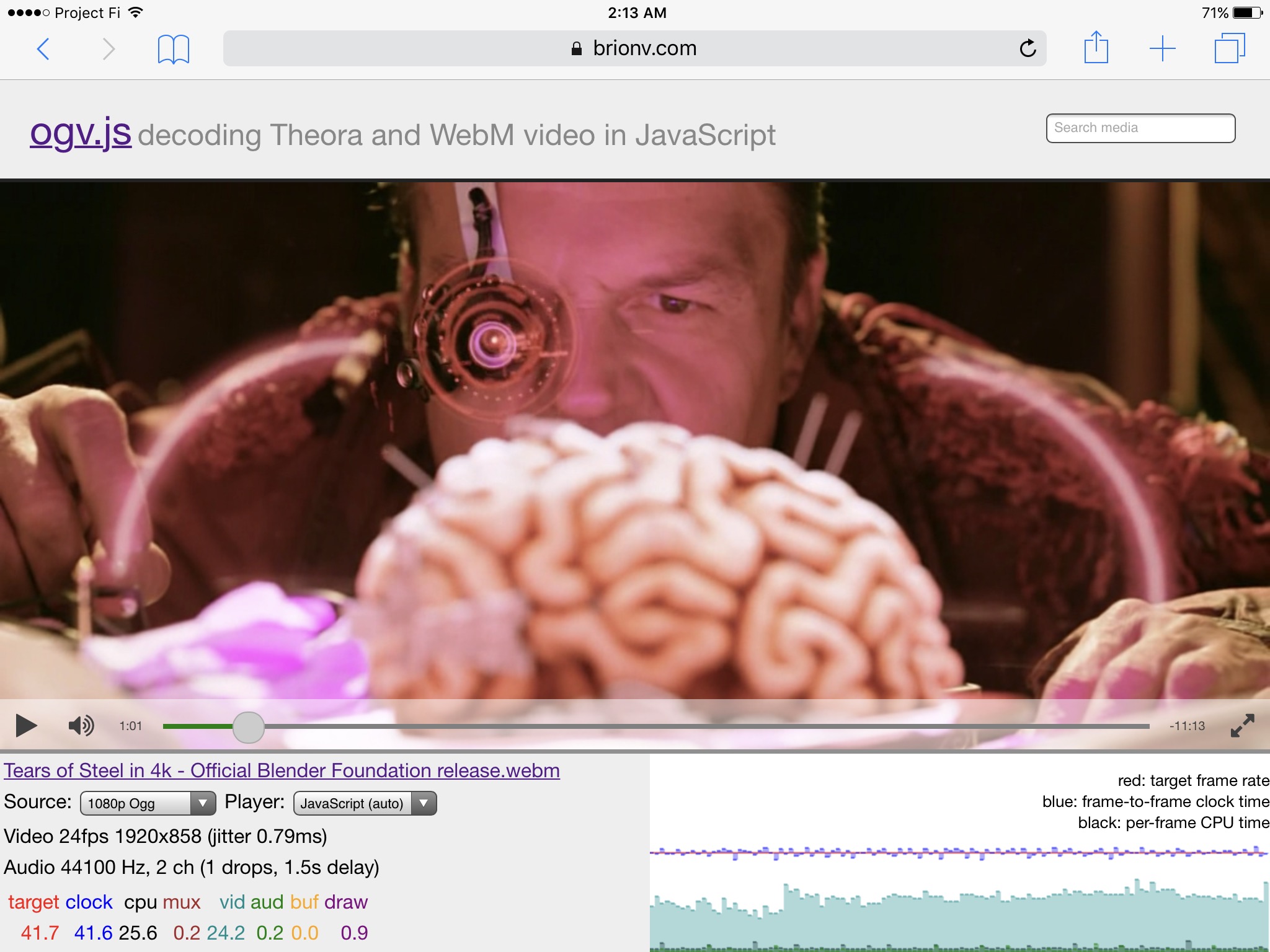
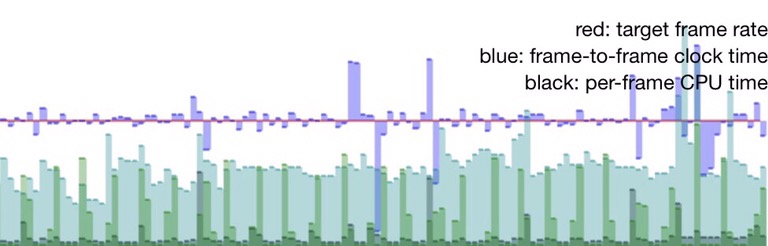
The performance graph shows frames consistently on time (blue line is near the red target line) and a fair amount of headroom on the video decode thread (cyan) with a tiny amount of time spent on the audio thread (green) and main thread (black).
At this and higher resolutions, everything is dominated by video decode time — if we can keep up with it we’re golden, but if we get behind everything would ssllooww ddoownn badly.
On an iPad Air, two models behind, we get similar performance on the 720p24 version, at about half the pixels:
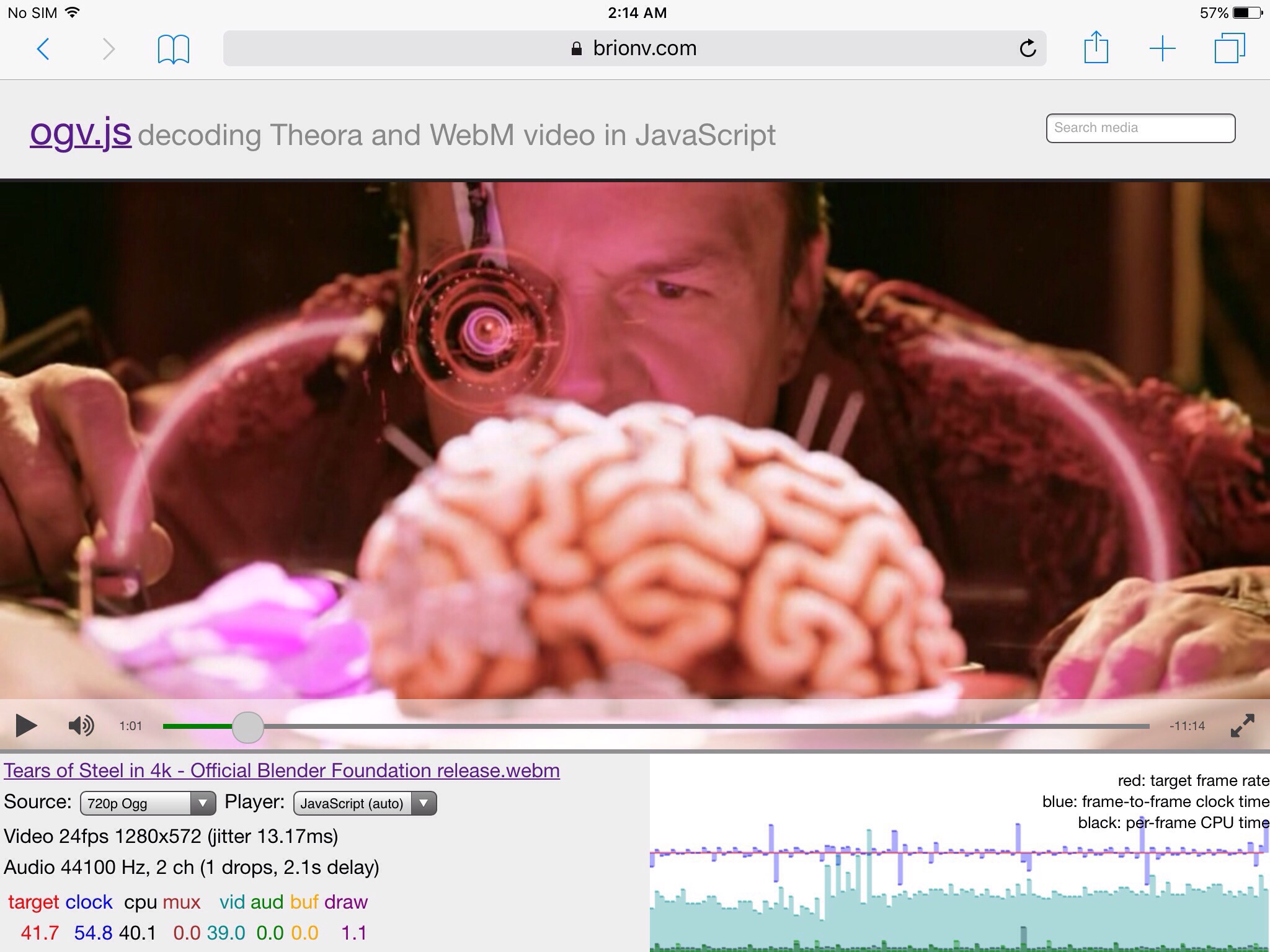
We can see the blue bars jumping up once a second, indicating sensitivity to the timing report and graph being updated once a second on the main thread, but overall still good. Audio in green is slightly higher but still ignorable.
On a much older iPad 3, another two models behind, we see a very different graph as we play back a mere 240p24 quarter-SD resolution file:
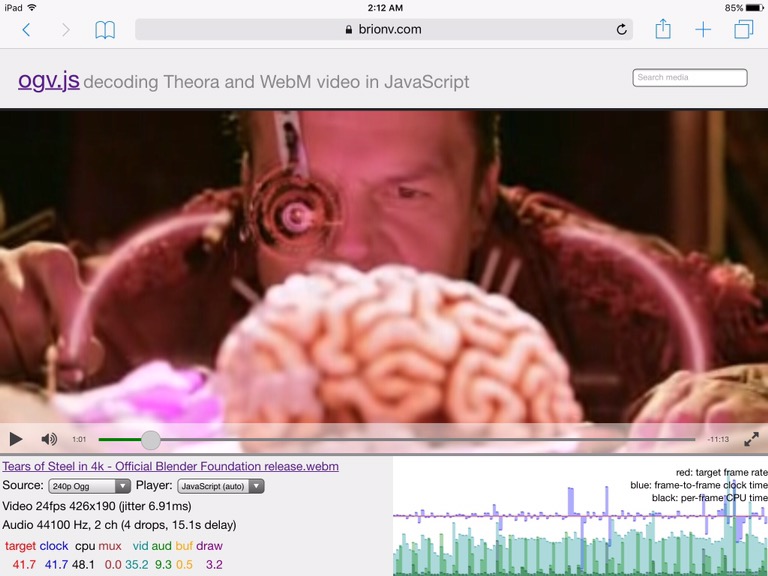
The iPad 3 has an older generation, 32-bit processor, and is in general pretty sluggish. Even at a low resolution, we have less headroom for the cyan bars of the video decode thread. Blue bars dipping below the red target line show we’re slipping on A/V sync sometimes. The green bars are much higher, indicating the audio decode thread is churning a lot harder to keep our buffers filled. Last but not least the gray bars at the bottom indicate more time spent in demuxing, drawing, etc on the main thread.
On this much slower processor, pushing audio decoding to another core makes a significant impact, saving an average of several milliseconds per frame by letting it overlap with video decoding.
The gray spikes from the main thread are from the demuxer, and after investigation turn out to be inflated by per-packet overhead on the tiny Vorbis audio packets… Such as adding timestamps to many of the packets. Ogg packs multiple small packets together into a single “page”, with only the final packet at the end of the page actually carrying a timestamp. Currently I’m using liboggz to encapsulate the demuxing, using its option to automatically calculate the missing timestamp deltas from header data in the packets… But this means every few frames the demuxer suddenly releases a burst of tiny packets with a 15-50ms delay on the main thread as it walks through them. On the slow end this can push a nearly late frame into late territory.
I may have further optimizations to make in keeping the main thread clear on slower CPUs, such as more efficient handling of download progress events, but overlapping the video and audio decode threads helps a lot.
On other machines like slow Windows boxes with blacklisted graphics drivers, we also benefit from firing off the next video decode before drawing the current frame — if WebGL is unexpectedly slow, or we fall back to CPU drawing, it may take a significant portion of our frame budget just to paint. Sending data down to the decode thread first means it’s more likely that the drawing won’t actually slow us down as much. This works wonders on a slow ARM-based Windows RT 8.1 Surface tablet. :)