Ugh, there really needs to be a sane way to package a “web” module that includes both JavaScript code and other assets (images, fonts, styles, Flash shims, and other horrors).
I’m cleaning up some code from my ogv.js JavaScript audio/video player, including breaking out the audio output and streaming URL input as separate modules for reuse… The audio output class is mostly a bit of JavaScript, but includes a Flash shim for IE 10/11 which requires bundling a .swf file and making it web-accessible.
Browserify can package up a virtual filesystem into your JS code — ok for loading a WebGL shader maybe — but can’t expose it to the HTML side of things where you want to reference a file by URL, especially if you don’t want it preloaded.
Bower will fetch everything from the modules you specify, but doesn’t distinguish clearly between files that should be included in the output (or what paths will be used to reference them) and random stuff in your repo. They kinda recommend using further tools to distill down an actual set of output…
Dear LazyWeb: Is there anything else in the state of the art that can make it a little easier to bundle together this sort of module into larger library or app distributions?
It’s technically a pretty nice system; they’re using clang to build your Objective-C code natively to the Universal Windows Platform as native x86 or ARM code, with an open-source implementation of (large parts of) Apple’s Foundation and UIKit APIs on top of UWP. Since you’re building native code, you also have full access to the Windows 10 APIs if you want to throw in some ‪#‎ifdefs‬.
I suspect there are a lot fewer ‘moving parts’ in it than were in the ‘Project Astoria’ Android bridge (which would have had to deal with Java etc), so in retrospect it’s not super surprising that they kept this one while canceling the Android bridge.
I don’t know if it’ll get used much other than for games that targeted iOS first and want to port to Xbox One and Windows tablets easily, but it’s a neat idea.
Probably tricky to get something like the Wikipedia app working since that app does lots of WebView magic etc that’s probably a bad API fit… but might be fun to play with!
The basic data model for the main content dumps hasn’t changed much in 10 years or so, when I switched us from raw blobs of SQL ‘INSERT’ statements to an XML data stream in order to abstract away upcoming storage schema changes… fields have been added over the years, and there have been some changes in how the dumps are generated to partially parallelize the process but the core giant-XML-stream model is scaling worse and worse as our data sets continue to grow.
One possibility is to switch away from the idea of producing a single data snapshot in a single or small set of downloadable files… perhaps to a model more like a software version control system, such as git.
Specific properties that I think will help:
the master data set can change often, in small increments (so can fetch updates frequently)
updates along a branch are ordered, making updates easier to reason about
local data set can be incrementally updated from the master data set, no matter how long between updates (so no need to re-download entire .xml.bz2 every month)
network protocol for updates, and access to versioned storage within the data set can be abstracted behind a common tool or library (so you don’t have to write Yet Another Hack to seek within compressed stream or Yet Another Bash Script to wget the latest files)
Some major open questions:
Does this model sound useful for people actually using Wikipedia data dumps in various circumstances today?
What help might people need in preparing their existing tools for a switch to this kind of model?
Does it make sense to actually use an existing VCS such as git itself? Or are there good reasons to make something bespoke that’s better-optimized for the use case or easier to embed in more complex cross-platform tools?
When dealing with data objects removed from the wiki databases for copyright/privacy/legal issues, does this have implications for the data model and network protocol?
git’s crypto-hash-based versioning tree may be tricky here
Do we need a way to both handle the “fast-forward” updates of local to master and to be able to revert back locally (eg to compare current and old revisions)
Technical issues in updating the master VCS from the live wikis?
Push updates immediately from MediaWiki hook points, or use an indirect notify+pull?
Does RCStream expose enough events and data already for the latter, or something else needed to ‘push’?
Can update jobs for individual revisions be efficient enough or do we need more batching?
Heads-up San Francisco peeps — I’ll be heading into town next week to help my fellow Wikimedia Foundation folks talk and process and plan and generally help turn what’s been an unfortunate leadership and communication crisis into a chance to really make improvements. I’ve been really impressed and inspired by the mails and posts and discussions I’ve seen internally and externally, and I’m really proud of the maturity and understanding you have all shown. Wikimedians and staffers of all stripes, y’all are awesome and we’re going to come through this stronger, both within the company and in the broader movement community.
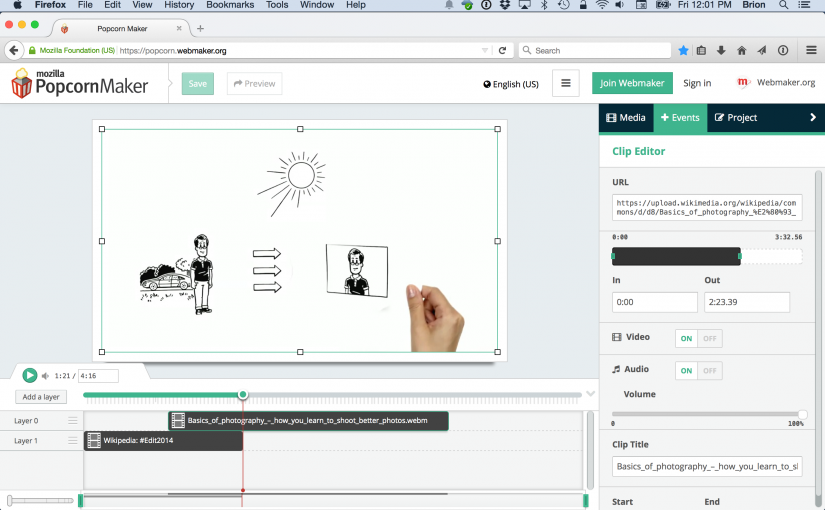
One of the really cool ‘web maker’ projects that Mozilla sponsored in the last few years was Popcorn Maker, an in-browser video editor that could take direct video clips or videos from Youtube etc and let you remix to your heart’s content.
If you’re interested in helping out, we’re going to have some work sprints at WikiConference USA next weekend in Washington, DC. Please come and help out!
“It’s an older codec, but it checks out. I was about to let them through.”
This first generation uses the Ogg Theora video codec, which we started using on Wikipedia “back in the day” before WebM and MP4/H.264 started fighting it out for dominance of HTML5 video. In fact, Ogg Theora/Vorbis were originally proposed as the baseline standard codecs for HTML5 video and audio elements, but Apple and Microsoft refused to implement it and the standard ended up dropping a baseline requirement altogether.
Ah, standards. There’s so many to choose from!
I’ve got preliminary support for WebM in ogv.js; it needs more work but the real blocker is performance. WebM’s VP8 and newer VP9 video codecs provide much better quality/compression ratios, but require more CPU horsepower to decode than Theora… On a fast MacBook Pro, Safari can play back ‘Llama Drama’ in 1080p Theora but only hits 480p in VP8.
Llama drama in Theora 1080p
That’s about a 5x performance gap in terms of how many pixels we can push…Â For now, the performance boost from using an older codec is worth it, as it gets older computers and 64-bit mobile devices into the game.
But it also means that to match quality, we have to double the bitrate — and thus bandwidth – of Theora output versus VP8 at the same resolution. So in the longer term, it’d be nice to get VP8 — or the newer VP9 which halves bitrate again — working well enough on ogv.js.
emscripten: making ur C into JS
ogv.js’s player logic is handwritten JavaScript, but the guts of the demuxer and decoders are cross-compiled from well-supported, battle-tested C libraries.
Emscripten is a magical tool developed at Mozilla to help port large C/C++ codebases like games to the web platform. In short, it runs your C/C++ code through the well-known clang compiler, but instead of producing native code it uses a custom LLVM backend that produces JavaScript code that can run in any modern browser or node.js.
Awesome town. But what are the limitations and pain points?
Integer math
Readers with suitably arcane knowledge may be aware that JavaScript has only one numeric type: 64-bit double-precision floating-point.
This is “convenient” for classic scripting in that you don’t have to worry about picking the right numeric type, but it has several horrible, horrible consequences:
When you really wanted 32-bit integers, floating-point math is going to be much slower
When you really wanted 64-bit integers, floating-point math is going to lose precision if your numbers are too big… so you have to emulate with 32-bit integers
If you relied on the specific behavior of 32-bit integer multiplication, you may have to use a slow polyfill of Math.imul
Luckily, because of #1 above, JavaScript JIT compilers have gone to some trouble to optimize common integer math operations. That is, JavaScript engines do support integer types and integer math, just you don’t know for sure when you have an integer at the source level.
Did I say “luckily”? :P
So this leads to one more ugly consequence:
In order to force the JIT compiler to run integer math, emscripten output coerces types constantly — “(x|0)” to force to 32-bit int, or “+x” to force to 64-bit float.
This actually performs well once it’s through the JIT compiler, but it bloats the .js code that we have to ship to the browser.
The heap is an island
Emscripten provides a C-like memory model by using Typed Arrays: a single ArrayBuffer provides a heap that can be read/written directly as various integer and floating point types.
However…
Because all pointers are indexes into the heap, there’s no way for C code to reference data in an external ArrayBuffer or other structure. This is obviously an issue when your video codec needs to decode a data packet that’s been passed to it from JavaScript!
Currently I’m simply copying the input packets into emscripten’s heap in a wrapper function, then calling the decoder on the copy. This works, but the extra copy makes me sad. It’s also relatively slow in Internet Explorer, where the copy implementation using Uint8Array.set() seems to be pretty inefficient.
Getting data out can be done “zero-copy” if you’re careful, by creating a typed-array subview of the emscripten heap; this can be used for instance to upload a WebGL texture directly from the decoder. Neat!
But, that trick doesn’t work when you need to pass data between worker threads.
Workers of the JavaScript world, unite!
Parallel computing is now: these days just about everything from your high-end desktop to your low-end smartphone has at least two CPU cores and can perform multiple tasks in parallel.
Unfortunately, despite half a century of computer science research and a good decade of marketplace factors, doing parallel programming well is still a Hard Problem.
Regular JavaScript provides direct access to only a single thread of execution, which keeps things simple but can be a performance bottleneck. Browser makers introduced Web Workers to fill this gap without introducing the full complexities of shared-memory multithreading…
Essentially, each Worker is its own little JavaScript universe: the main thread context can’t access data in a Worker directly, and the Worker can’t access data from the main context. Neither can one thread cause the other to block… So to communicate between threads, you have to send asynchronous messages.
This is actually a really nice model that reduces the number of ways you can shoot yourself in the foot with multithreading!
But, it maps very poorly to C/C++ threads, where you start with shared memory and foot-shooting and try to build better abstractions on top of that.
So, we’re not yet able to make use of any multithreaded capabilities in the actual decoders. :(
But, we can run the decoders themselves in Worker threads, as long as they’re factored into separate emscripten subprograms. This keeps the main thread humming smoothly even when video decoding is a significant portion of wall-clock time, and can provide a little bit of actual parallelism by running video and audio decoding at the same time.
The Theora and VP8 decoders currently have no inherent multithreading available, but VP9 can so that’s worth looking out for in the future…
Some browser makers are working on providing an “opt-in” shared-memory threading model through an extended ‘SharedArrayBuffer’ that emscripten can make use of, but this is not yet available in any of my target browsers (Safari, IE, Edge).
Waiting for SIMD
Modern CPUs provide SIMD instructions (“Single Instruction Multiple Data”) which can really optimize multimedia operations where you need to do the same thing a lot of times on parallel data.
Codec libraries like libtheora and libvpx use these optimized instructions explicitly in key performance hotspots when compiling to native code… but how do you deal with this when compiling via JavaScript?
But, my main targets (Safari, IE, Edge) don’t support SIMD in JS yet so I haven’t started…
GPU Madness
The obvious next thing to ask is “Hey what about the GPU?” Modern computers come with amazing high-throughput parallel-processing graphics units, and it’s become quite the rage to GPU accelerate everything from graphics to spreadsheets.
The good news is that current versions of all main browsers support WebGL, and ogv.js uses it if available to accelerate drawing and YCbCr-RGB colorspace conversion.
The bad news is that’s all we use it for so far — the actual video decoding is all on the CPU.
It should be possible to use the GPU for at least parts of the video decoding steps. But, it’s going to require jumping through some hoops…
WebGLÂ doesn’t provide general-purpose compute shaders, so would have to shovel data into textures and squish computation into fragment shaders meant for processing pixels.
WebGL is only available on the main thread, so if decoding is done in a worker there’ll be additional overhead shipping data between threads
If we have to read data back from the GPU, that can be slow and block the CPU, dropping efficiency again
The codec libraries aren’t really set up with good GPU offloading points in them, so this may be Hard To Do.
In the meantime, I’ve got lots of other things to fix in Wikipedia’s video support so will be concentrating on that stuff, but will keep on improving this as the JS platform evolves!
ogv.js provides a JavaScript compatibility shim for Ogg audio and video playback in Safari 6.1 and higher, IE 10/11, and Microsoft Edge browsers, which gets Wikipedia’s media files working in those browsers. (Due to patent licensing concerns, we don’t provide files in the common MP3 or MP4 H.264/AAC formats, and this has made it difficult to use media files reliably across browsers as Apple and Microsoft have not adopted the free Ogg or WebM formats.)
See list of pending fixes for additional improvements that should go out next week, after which I’ll make wider announcements.
Here, have some samples! In Firefox, Chrome, or Opera these will “just work” with native WebM playback, while in Safari/IE/Edge they will “just work” with JavaScript Ogg playback:
I’ve been cleaning up MediaWiki’s “TimedMediaHandler” extension in preparation for merging integration with my ogv.js JavaScript media player for Safari and IE/Edge when no native WebM or Ogg playback is available. It’s coming along well, but one thing continued to worry me about performance: when things worked it was great, but if the video decode was too slow, it could make your browser very sluggish.
In addition to simply selecting too high a resolution for your CPU, this can strike if you accidentally open a debug console during playback (Safari, IE) or more seriously if you’re on an obscure platform that doesn’t have a JavaScript JIT compiler… or using an app’s embedded browser on your iPhone.
Or simply if the integration code’s automatic benchmark overestimated your browser speed, running too much decoding just made everything crap.
Luckily, the HTML5 web platform has a solution — Web Workers.
Workers provide a limited ability to do multithreading in JavaScript, which means the decoder thread can take as long as it wants — the main browser thread can keep responding to user input in the meantime.
The limitation is that scripts running in a Worker have no direct access to your code or data running in the web page’s main thread — you can communicate only by sending messages with ‘raw’ data types. Folks working with lots of DOM browser nodes thus can’t get much benefit, but for buffer-driven compute tasks like media decoding it’s perfect!
Threading comms overhead
My first attempt was to take the existing decoder class (an emscripten module containing the Ogg demuxer, Theora video decoder, and Vorbis audio decoder, etc) and run it in the worker thread, with a proxy object sending data and updated object properties back and forth.
This required a little refactoring to make the decoder interfaces asynchronous, taking callbacks instead of returning results immediately.
It worked pretty well, but there was a lot of overhead due to the demuxer requiring frequent back-and-forth calls — after every processing churn, we had to wait for the demuxer to return its updated status to us on the main thread.
This only took a fraction of a millisecond each time, but a bunch of those add up when your per-frame budget is 1/30 (or even 1/60) second!
I had been intending a bigger refactor of the code anyway to use separate emscripten modules for the demuxer and audio/video decoders — this means you don’t have to load code you won’t need, like the Opus audio decoder when you’re only playing Vorbis files.
It also means I could change the coupling, keeping the demuxer on the main thread and moving just the audio/video decoders to workers.
This gives me full speed going back-and-forth on the demuxer, while the decoders can switch to a more “streaming” behavior, sending packets down to be decoded and then displaying the frames or queueing the audio whenever it comes back, without having to wait on it for the next processing iteration.
The result is pretty awesome — in particular on older Windows machines, IE 11 has to use the Flash plugin to do audio and I was previously seeing a lot of “stuttery” behavior when the video decode blocked the Flash audio queueing or vice versa… now it’s much smoother.
The main bug left in the worker mode is that my audio/video sync handling code doesn’t properly handle the case where video decoding is consistently too slow — when we were on the main thread, this caused the audio to halt due to the main thread being blocked; now the audio just keeps on going and the video keeps playing as fast as it can and never catches up. :)
However this should be easy to fix, and having it be wrong but NOT FREEZING YOUR BROWSER is an improvement over having sync but FREEZING YOUR BROWSER. :)
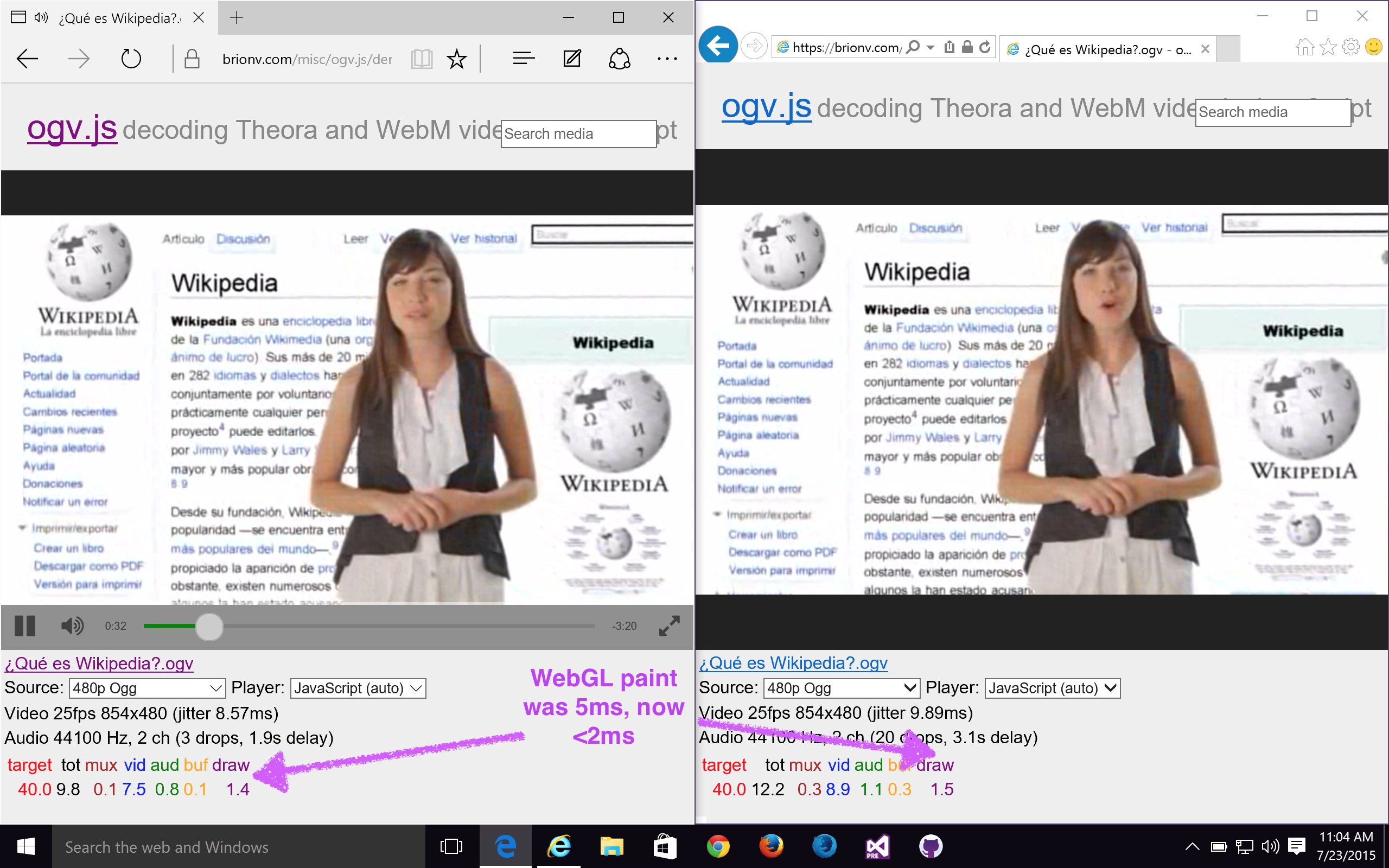
One of my pet projects is ogv.js, a video/audio decoder and player in JavaScript powered by codec libraries ported from C with Mozilla’s emscripten transpiler. I’m getting pretty close to a 1.0 release and deploying it to Wikimedia Commons to provide plugin-free Ogg (and experimentally WebM) playback on Apple’s Safari and Microsoft’s Internet Explorer and Edge browsers (the only major browsers lacking built-in WebM video support).
In cleaning it up for release, I’ve noticed some performance regressions on IE and Edge due to cleaning out old code I thought was no longer needed.
In particular, I found that drawing and YUV-RGB colorspace conversion using WebGL, which works fantastically fast in Safari, Chrome, and Firefox, was about as slow as on-CPU JavaScript color conversion in IE 11 and Edge — luckily I had a hack in store that works around the bottleneck.
As it turns out, I had had some older code to stuff things into RGBA textures and then unpack them in a shader for IE 10 and the original release of IE 11, which did not support LUMINANCE or ALPHA texture uploads! I had removed this code to simplify my WebGL code paths since LUMINANCE got added in IE 11 update 1, but hadn’t originally noticed the performance regression.