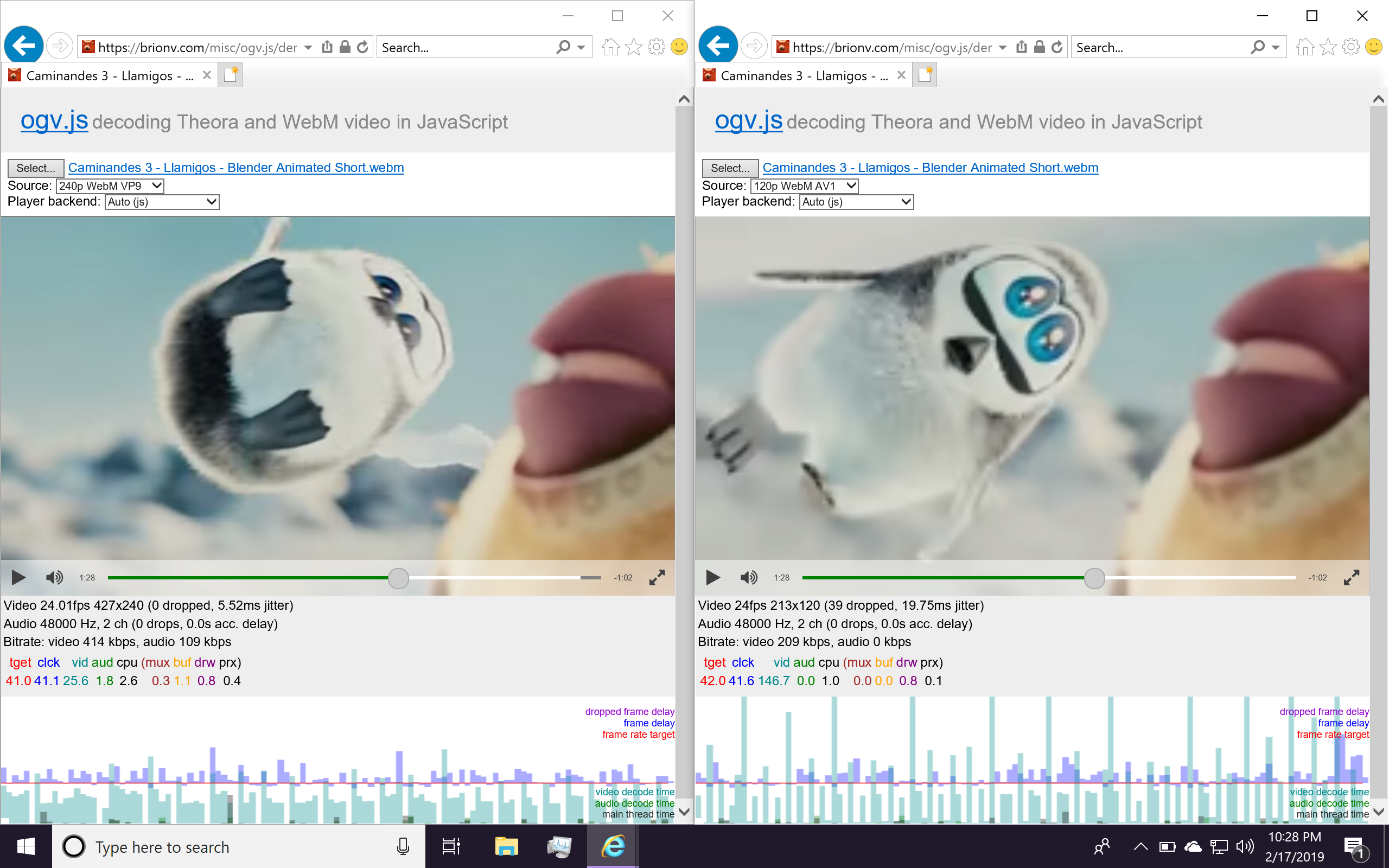
After some additional fixes and experiments I’ve tagged ogv.js 1.6.0 and released it. As usual you can use ‘ogv’ package on npm or fetch the zip manually. This includes various fixes, including for some weird bugs!, and performance improvements on lower-end machines. Internals have been partially refactored to aid future maintenance, and experimental AV1 decoding has been added using VideoLAN’s dav1d decoder.
dav1d and SIMD
The dav1d AV1 decoder is now working pretty solidly, but slowly. I found that my test files were encoded at too high a quality and dialed them back to my actual target bitrate and find that performance improves as a consequence, so hey! Not bad. ;)
I’ve worked around a minor compiler issue in emscripten’s old “fastcomp” asm.js->wasm backend where an inner loop didn’t get unrolled, which improves decode performance by a couple percent. Upstream prefers to let the unroll be implicit, so I’m keeping this patch in a local fork for now.
I’ve also been reached out to by some folks working on the WebAssembly SIMD proposal, which should allow speeding up some of the slow filtering operations with optimized vector code! The only browser implementation of the proposal (which remains a bit controversial) is currently Chrome, with an experimental command-line flag, and the updated vectorization code is in the new WebAssembly compiler backend that’s integrated with upstream LLVM.
So I spent some time getting up and running on the new LLVM backend for emscripten, found a few issues:
- emsdk doesn’t update the LLVM download properly so you can get stuck on an old version and be very confused — this is being fixed shortly!
- currently it’s hard to use a single sdk installation for both modes at once, and asm.js compilation requires the old backend. So I’ve temporarily disabled the asm.js builds on my simd2 work branch.
- multithreaded builds are broken atm (at least modularized, which only just got fixed on the main compiler so might need fixes for llvm backend)
- use of atomics intrinsics in a non-multithreaded build results in a validation error, whereas it had been silently turned into something safe in the old backend. I had to patch dav1d with a “fake atomics” option to #define them away.
- Non-SIMD builds were coming out with data corruption, which I tracked down to an optimizer bug which had just been fixed upstream the day before I reported it. ;)
- I haven’t gotten as far as working with any of the SIMD intrinsics, because I’m getting a memory access out of bounds issue when engaging the autovectorizer. I narrowed down a test case with the first error and have reported it; not sure yet whether the problem is in the compiler or in Chrome/V8.
In theory autovectorization is likely to not do much, but significant gains could be made using intrinsics… but only so much, as the operations available are limited and it’s hard to tell what will be efficient or not.
Intermittent file breakages
Very rarely, some files would just break at a certain position in the file for reasons I couldn’t explain. I had one turn up during AV1 testing where a particular video packet that contained two frame OBUs had one OBU header appear ok and the second obviously corrupted. I tracked the corruption back from the codec to the demuxer to the demuxer’s input buffer to my StreamFile abstraction used for loading data from a seekable URL.
Turned out that the offending packet straddled a boundary between HTTP requests — between the second and third megabytes of the file, each requested as a separate Range-based XMLHttpRequest, downloaded as binary strings so the data can be accessed during progress events. But according to the network panel, the second and third megabytes looked fine…. but the *following* request turned up as 512 KiB. …What?
Dumping the binary strings of the second and third megabytes, I immediately realized what was wrong:
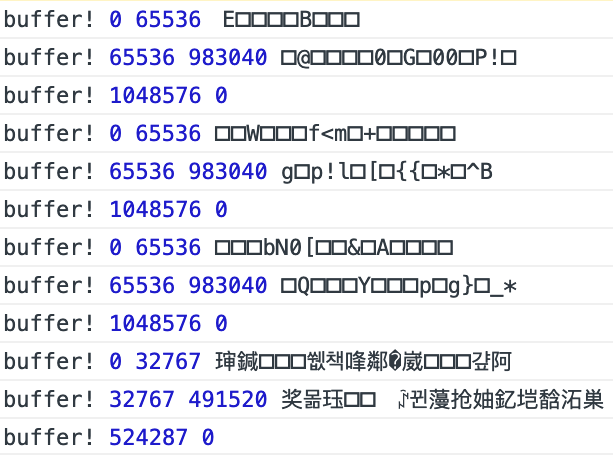
The first requests were as expected showing 8-bit characters (ASCII and control chars etc). The request with the broken packet was showing CJK characters indicating the string had probably been misinterpreted as UTF-16
It didn’t take much longer to confirm that the first two bytes of the broken request were 0xFE 0xFF, a UTF-16 Byte Order Mark. This apparently overrides the “overrideMimeType” method’s x-user-defined charset, and there’s no way to override it back. Hypothetically you could probably detect the case and swap bytes back but I think it’s not actually worth it to do full streaming downloads within chunks for the player — it’s better to buffer ahead so you can play reliably.
For now I’ve switched it to use ArrayBuffer XHRs instead of binary strings, which avoids the encoding problem but means data can’t be accessed until each chunk has finished downloading.