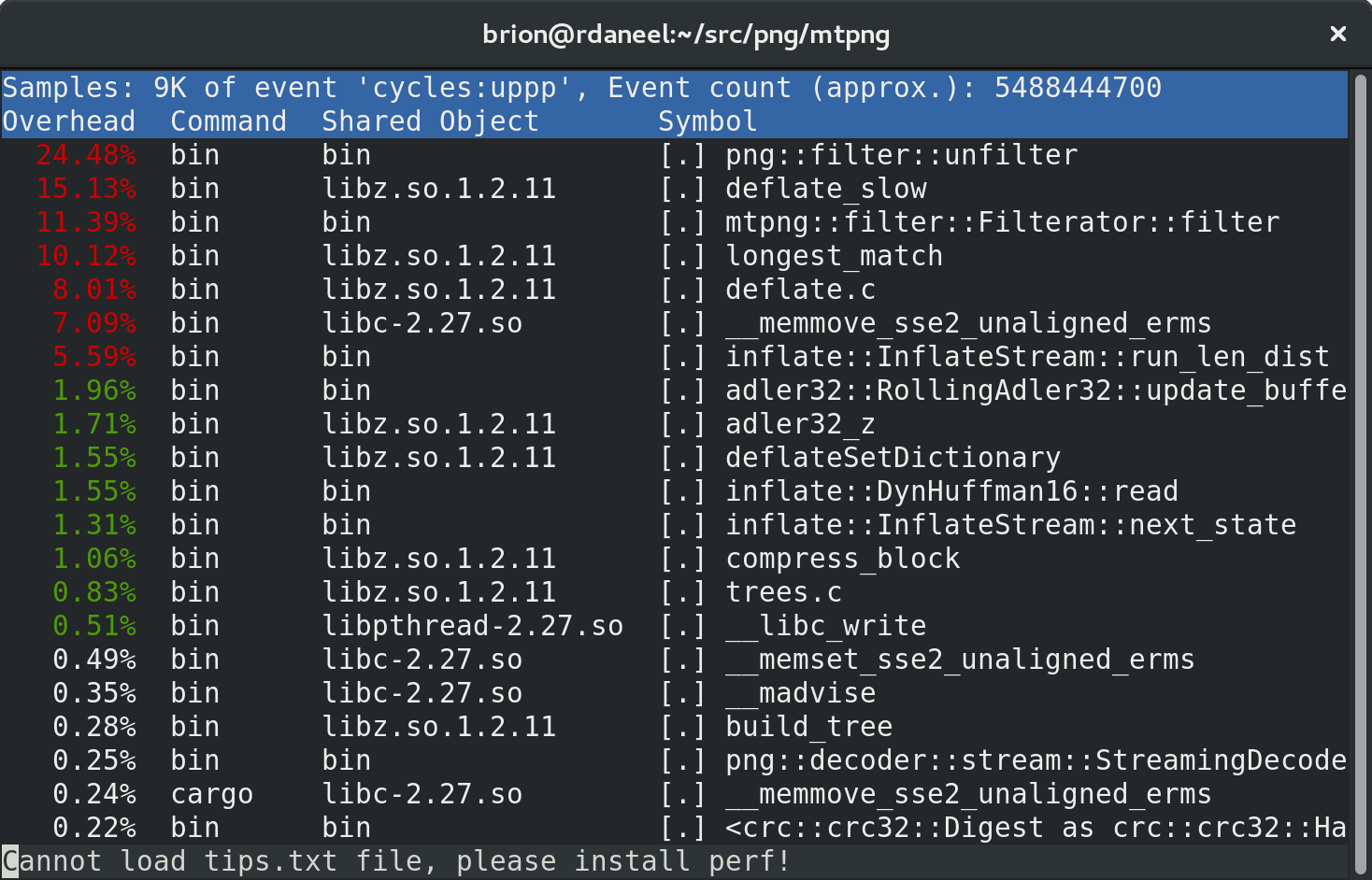
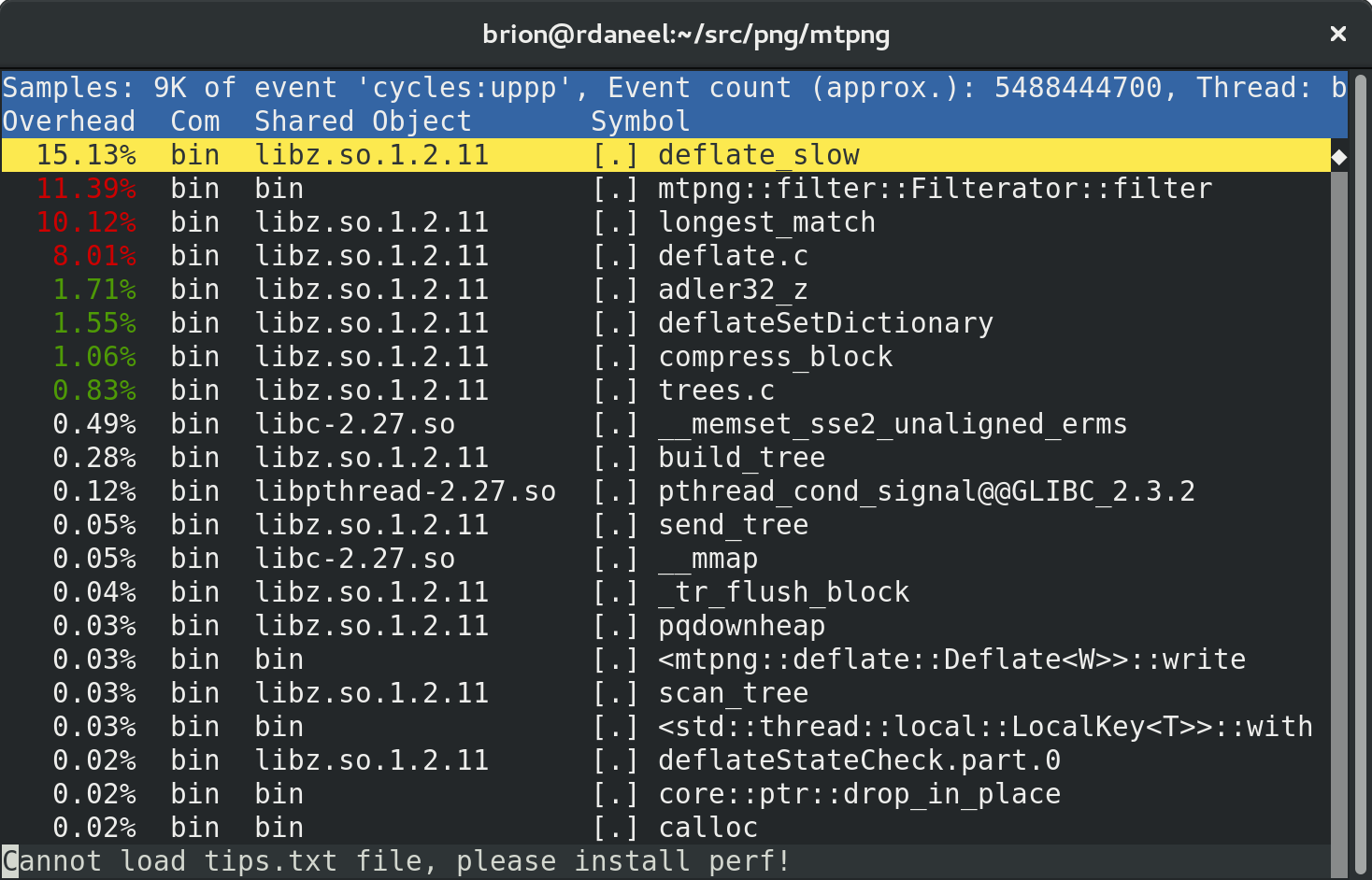
In my last posts I explored some optimization strategies inside the Rust code for mtpng, a multithreaded PNG encoder I’m creating. Now that it’s fast, and the remaining features are small enough to pick up later, let’s start working on a C API so the library can be used by C/C++-based apps.
If you search the web you’ll find a number of tutorials on the actual FFI-level interactions, so I’ll just cover a few basics and things that stood out. The real trick is in making a good build system; currently Rust’s “Cargo” doesn’t interact well with Meson, for instance, which really wants to build everything out-of-tree. I haven’t even dared touch autoconf. ;)
For now, I’m using a bare Makefile for Unix (Linux/macOS) and a batch file for Windows (ugh!) to drive the building of a C-API-exercising test program. But let’s start with the headers and FFI code!
Contracts first: make a header file
The C header file (“mtpng.h“) defines the types, constants, and functions available to users of the library. It defines the API contract, both in code and in textual comments because you can’t express things like lifetimes in C code. :)
Enums
Simple enums (“fieldless enums” as they’re called) can be mapped to C enums fairly easily, but be warned the representation may not be compatible. C enums usually (is that the spec or just usually??) map to the C ‘int’ type, which on the Rust side is known as c_int. (Clever!)
//
// Color types for mtpng_encoder_set_color().
//
typedef enum mtpng_color_t {
MTPNG_COLOR_GREYSCALE = 0,
MTPNG_COLOR_TRUECOLOR = 2,
MTPNG_COLOR_INDEXED_COLOR = 3,
MTPNG_COLOR_GREYSCALE_ALPHA = 4,
MTPNG_COLOR_TRUECOLOR_ALPHA = 6
} mtpng_color;So the representation is not memory-compatible with the Rust version, which explicitly specifies to fit in a byte:
#[derive(Copy, Clone)]
#[repr(u8)]
pub enum ColorType {
Greyscale = 0,
Truecolor = 2,
IndexedColor = 3,
GreyscaleAlpha = 4,
TruecolorAlpha = 6,
}If you really need to ship the enums around bit-identical, use #[repr(c_int)]. Note also that there’s no enforcement that enum values transferred over the FFI boundary will have valid values! So always use a checked transfer function on input like this:
impl ColorType {
pub fn from_u8(val: u8) -> io::Result<ColorType> {
return match val {
0 => Ok(ColorType::Greyscale),
2 => Ok(ColorType::Truecolor),
3 => Ok(ColorType::IndexedColor),
4 => Ok(ColorType::GreyscaleAlpha),
6 => Ok(ColorType::TruecolorAlpha),
_ => Err(other("Invalid color type value")),
}
}More complex enums can contain fields, and things get complex. For my case I found it simplest to map some of my mode-selection enums into a shared namespace, where the “Adaptive” value maps to something that doesn’t fit in a byte and so could not be valid, and the “Fixed” values map to their contained byte values:
#[derive(Copy, Clone)]
pub enum Mode<T> {
Adaptive,
Fixed(T),
}
#[repr(u8)]
#[derive(Copy, Clone)]
pub enum Filter {
None = 0,
Sub = 1,
Up = 2,
Average = 3,
Paeth = 4,
}maps to C:
typedef enum mtpng_filter_t {
MTPNG_FILTER_ADAPTIVE = -1,
MTPNG_FILTER_NONE = 0,
MTPNG_FILTER_SUB = 1,
MTPNG_FILTER_UP = 2,
MTPNG_FILTER_AVERAGE = 3,
MTPNG_FILTER_PAETH = 4
} mtpng_filter;And the FFI wrapper function that takes it maps them to appropriate Rust values.
Callbacks and function pointers
The API for mtpng uses a few callbacks, required for handling output data and optionally as a driver for input data. In Rust, these are handled using the Write and Read traits, and the encoder functions are even generic over them to avoid having to make virtual function calls.
In C, the traditional convention is followed of passing function pointers and a void* as “user data” (which may be NULL, or a pointer to a private state structure, or whatever floats your boat).
In the C header file, the callback types are defined for reference and so they can be validated as parameters:
typedef size_t (*mtpng_read_func)(void* user_data,
uint8_t* p_bytes,
size_t len);
typedef size_t (*mtpng_write_func)(void* user_data,
const uint8_t* p_bytes,
size_t len);
typedef bool (*mtpng_flush_func)(void* user_data);On the Rust side we must define them as well:
pub type CReadFunc = unsafe extern "C"
fn(*const c_void, *mut uint8_t, size_t) -> size_t;
pub type CWriteFunc = unsafe extern "C"
fn(*const c_void, *const uint8_t, size_t) -> size_t;
pub type CFlushFunc = unsafe extern "C"
fn(*const c_void) -> bool;Note that the function types are defined as unsafe (so must be called from within an unsafe { … } block or another unsafe function), and extern “C” which defines them as using the platform C ABI. Otherwise the function defs are pretty standard, though they use C-specific types from the libc crate.
Note it’s really important to use the proper C types because different platforms may have different sizes of things. Not only do you have the 32/64-bit split, but 64-bit Windows has a different c_long type (32 bits) than 64-bit Linux or macOS (64 bits)! This way if there’s any surprises, the compiler will catch it when you build.
Let’s look at a function that takes one of those callbacks:
extern mtpng_result
mtpng_encoder_write_image(mtpng_encoder* p_encoder,
mtpng_read_func read_func,
void* user_data);#[no_mangle]
pub unsafe extern "C"
fn mtpng_encoder_write_image(p_encoder: PEncoder,
read_func: Option<CReadFunc>,
user_data: *const c_void)
-> CResult
{
if p_encoder.is_null() {
CResult::Err
} else {
match read_func {
Some(rf) => {
let mut reader = CReader::new(rf, user_data);
match (*p_encoder).write_image(&mut reader) {
Ok(()) => CResult::Ok,
Err(_) => CResult::Err,
}
},
_ => {
CResult::Err
}
}
}
}Note that in addition to the unsafe extern “C” we saw on the function pointer definitions, the exported function also needs to use #[no_mangle]. This marks it as using a C-compatible function name, otherwise the C linker won’t find it by name! (If it’s an internal function you want to pass by reference to C, but not expose as a symbol, then you don’t need that.)
Notice that we took an Option<CReadFunc> as a parameter value, not just a CReadFunc. This is needed so we can check for NULL input values, which map to None. while valid values map to Some(CReadFunc). (The actual pointer to the struct is more easily checked for NULL, since that’s inherent to pointers.)
The actual function is passed into a CReader, a struct that implements the Read trait by calling the function pointer:
pub struct CReader {
read_func: CReadFunc,
user_data: *const c_void,
}
impl CReader {
fn new(read_func: CReadFunc,
user_data: *const c_void)
-> CReader
{
CReader {
read_func: read_func,
user_data: user_data,
}
}
}
impl Read for CReader {
fn read(&mut self, buf: &mut [u8]) -> io::Result<usize> {
let ret = unsafe {
(self.read_func)(self.user_data,
&mut buf[0],
buf.len())
};
if ret == buf.len() {
Ok(ret)
} else {
Err(other("mtpng read callback returned failure"))
}
}
}Opaque structs
Since I’m not exposing any structs with public fields, I’ve got a couple of “opaque struct” types on the C side which are used to handle pointing at the Rust structs from C. Not a lot of fancy-pants work is needed to marshal them; the pointers on the C side pass directly to pointers on the Rust side and vice versa.
typedef struct mtpng_threadpool_struct
mtpng_threadpool;
typedef struct mtpng_encoder_struct
mtpng_encoder;One downside of opaque structs on the C side is that you cannot allocate them on the stack, because the compiler doesn’t know how big they are — so we must allocate them on the heap and explicitly release them.
In Rust, it’s conventional to give structs an associated “new” method, and/or wrap them in a builder pattern to set up options. Here I wrapped Rayon’s ThreadPool builder with a single function that takes a number of threads, boxes it up on the heap, and returns a pointer to the heap object:
extern mtpng_result
mtpng_threadpool_new(mtpng_threadpool** pp_pool,
size_t threads);pub type PThreadPool = *mut ThreadPool;
#[no_mangle]
pub unsafe extern "C"
fn mtpng_threadpool_new(pp_pool: *mut PThreadPool,
threads: size_t)
-> CResult
{
if pp_pool.is_null() {
CResult::Err
} else {
match ThreadPoolBuilder::new().num_threads(threads).build() {
Ok(pool) => {
*pp_pool = Box::into_raw(Box::new(pool));
CResult::Ok
},
Err(_err) => {
CResult::Err
}
}
}
}The real magic here is Box::into_raw() which replaces the Box<ThreadPool> smart pointer with a raw pointer you can pass to C. This means there’s no longer any smart management or releasing, so it’ll outlive the function… and we need an explicit release function:
extern mtpng_result
mtpng_threadpool_release(mtpng_threadpool** pp_pool);#[no_mangle]
pub unsafe extern "C"
fn mtpng_threadpool_release(pp_pool: *mut PThreadPool)
-> CResult
{
if pp_pool.is_null() {
CResult::Err
} else {
drop(Box::from_raw(*pp_pool));
*pp_pool = ptr::null_mut();
CResult::Ok
}
}
Box::from_raw() turns the pointer back into a Box<ThreadPool>, which de-allocates the ThreadPool at the end of function scope.
Lifetimes
Annotating object lifetimes in this situation is ….. confusing? I’m not sure I did it right at all. The only lifetime marker I currently use is the for thread pool, which must live at least as long as the encoder struct.
As a horrible hack I’ve defined the CEncoder to use static lifetime for the threadpool, which seems …. horribly wrong. I probably don’t need to do it like this. (Guidance and hints welcome! I will update the post and the code! :D)
// Cheat on the lifetimes?
type CEncoder = Encoder<'static, CWriter>;Then the encoder creation, which takes an optional ThreadPool pointer and required callback function pointers, looks like:
extern mtpng_result
mtpng_encoder_new(mtpng_encoder** pp_encoder,
mtpng_write_func write_func,
mtpng_flush_func flush_func,
void* const user_data,
mtpng_threadpool* p_pool);
pub type PEncoder = *mut CEncoder;
#[no_mangle]
pub unsafe extern "C"
fn mtpng_encoder_new(pp_encoder: *mut PEncoder,
write_func: Option<CWriteFunc>,
flush_func: Option<CFlushFunc>,
user_data: *const c_void,
p_pool: PThreadPool)
-> CResult
{
if pp_encoder.is_null() {
CResult::Err
} else {
match (write_func, flush_func) {
(Some(wf), Some(ff)) => {
let writer = CWriter::new(wf, ff, user_data);
if p_pool.is_null() {
let encoder = Encoder::new(writer);
*pp_encoder = Box::into_raw(Box::new(encoder));
CResult::Ok
} else {
let encoder = Encoder::with_thread_pool(writer, &*p_pool);
*pp_encoder = Box::into_raw(Box::new(encoder));
CResult::Ok
}
},
_ => {
CResult::Err
}
}
}
}Note how we take the p_pool pointer and turn it into a Rust reference by dereferencing the pointer (*) and then re-referencing it (&). :)
Because we’re passing the thread pool across a safe/unsafe boundary, it’s entirely the caller’s responsibility to uphold the compiler’s traditional guarantee that the pool instance outlives the encoder. There’s literally nothing to stop it from being released early by C code.
Calling from C
Pretty much all the external-facing functions return a a result status enum type, which I’ve mapped the Rust Result<_,Error(_)> system into. For now it’s just ok or error states, but will later add more detailed error codes:
Since C doesn’t have a convenient “?” syntax or try! macro for trapping those, I wrote a manual TRY macro for my samples’s main(). Ick!
#define TRY(ret) { \
mtpng_result _ret = (ret); \
if (_ret != MTPNG_RESULT_OK) { \
fprintf(stderr, "Error: %d\n", (int)(_ret)); \
retval = 1; \
goto cleanup; \
}\
}The calls are then wrapped to check for errors:
int main() {
... some state setup ...
mtpng_threadpool* pool;
TRY(mtpng_threadpool_new(&pool, threads));
mtpng_encoder* encoder;
TRY(mtpng_encoder_new(&encoder,
write_func,
flush_func,
(void*)&state,
pool));
TRY(mtpng_encoder_set_chunk_size(encoder, 200000));
TRY(mtpng_encoder_set_size(encoder, 1024, 768));
TRY(mtpng_encoder_set_color(encoder, color_type, depth));
TRY(mtpng_encoder_set_filter(encoder, MTPNG_FILTER_ADAPTIVE));
TRY(mtpng_encoder_write_header(encoder));
TRY(mtpng_encoder_write_image(encoder, read_func, (void*)&state));
TRY(mtpng_encoder_finish(&encoder));
cleanup:
if (encoder) {
TRY(mtpng_encoder_release(&encoder));
}
if (pool) {
TRY(mtpng_threadpool_release(&pool));
}
printf("goodbye\n");
return retval;
}Ok, mostly straightforward right? And if you don’t like the TRY macro you can check error returns manually, or whatever. Just don’t forget to check them! :D
Error state recovery other than at API boundary checks may or may not be very good right now, I’ll clean that up later.
Now I’m pretty sure some things will still explode if I lean the wrong way on this system. For instance looking above, I’m not convinced that the pointers on the stack will be initialized to NULL except on debug builds. :D
Don’t forget the callbacks
Oh right, we needed read and write callbacks! Let’s put those back in. Start with a state structure we can use (it doesn’t have to be the same state struct for both read and write, but it is here cause why not?)
typedef struct main_state_t {
FILE* out;
size_t width;
size_t bpp;
size_t stride;
size_t y;
} main_state;
static size_t read_func(void* user_data,
uint8_t* bytes,
size_t len)
{
main_state* state = (main_state*)user_data;
for (size_t x = 0; x < state->width; x++) {
size_t i = x * state->bpp;
bytes[i] = (x + state->y) % 256;
bytes[i + 1] = (2 * x + state->y) % 256;
bytes[i + 2] = (x + 2 * state->y) % 256;
}
state->y++;
return len;
}
static size_t write_func(void* user_data,
const uint8_t* bytes,
size_t len)
{
main_state* state = (main_state*)user_data;
return fwrite(bytes, 1, len, state->out);
}
static bool flush_func(void* user_data)
{
main_state* state = (main_state*)user_data;
if (fflush(state->out) == 0) {
return true;
} else {
return false;
}
}Couple of things stand out to me: first, this is a bit verbose for some common cases.
If you’re generating input row by row like in this example, or reading it from another source of data, the read callback works ok though you have to set up some state. If you already have it in a buffer, it’s a lot of extra hoops. I’ve added a convenience function for that, which I’ll describe in more detail in a later post due to some Rust-side oddities. :)
And writing to a stdio FILE* is probably really common too. So maybe I’ll set up a convenience function for that? Don’t know yet.
Building the library
Oh right! We have to build this code don’t we, or it won’t actually work.
Start with the library itself. Since we’re creating everything but the .h file in Rust-land, we can emit a shared library directly from the Cargo build system by adding a ‘cdylib’ target. In our Cargo.toml:
[lib]
crate-type = ["rlib", "cdylib"]The “rlib” is a regular Rust library; the “cdylib” is a C-compatible shared library that exports only the C-compatible public symbols (mostly). The rest of the Rust standard library (the parts that get used) are compiled statically inside the cdylib, so they don’t interfere with other libraries that might have been built in a similar way.
Note this means that while a Rust app that uses mtpng and another rlib can share a Rayon ThreadPool instance, a C app that uses mtpng and another cdylib cannot share ThreadPools because they might be different versions etc.
Be warned that shared libraries are complex beasts, starting with the file naming! On Linux and most other Unix systems, the output file starts with “lib” and ends with “.so” (libmtpng.so). But on macOS, it ends in “.dylib” (libmtpng.dylib). And on Windows, you end up with both “mtpng.dll” which is linked at runtime and an “mtpng.dll.lib” which is linked at compile time (and really should be “mtpng.lib” to follow normal conventions on Windows, I think).
I probably should wrap the C API and the cdylib output in a feature flag, so it’s not added when building pure-Rust apps. Todo!
For now, the Makefile or batch file are invoking Cargo directly, and building in-tree. To build cleanly out of tree there are some options on Cargo to specify the target dir and (in nightly toolchain) the work output dir. This seems to be a work in progress, so I’m not worrying about the details too much yet, but if you need to get something working soon that integrates with autotools, check out GNOME’s librsvg library which has been migrating code from C to Rust over the last couple years and has some relevant build hacks. :)
Once you have the output library file(s), you put them in the appropriate place and use the appropriate system-specific magic to link to them in your C program like for any shared library.
The usual gotchas apply:
- Unix (Linux/macOS) doesn’t like libraries that aren’t in the standard system locations. You have to add an -L param with the path to the library to your linker flags to build against the library in-tree or otherwise not standardly located.
- Oh and Unix also hates to load libraries at runtime for the same reason! Use LD_LIBRARY_PATH or DYLD_LIBRARY_PATH when running your executable. Sigh.
- But sometimes macOS doesn’t need that because it stores the relative path to your library into your executable at link time. I don’t even understand that Mach-O format, it’s crazy! ;)
- Windows will just load any library out of the current directory, so putting mtpng.dll in with your executable should work. Allll right!
It should also be possible to build as a C-friendly static library, but I haven’t fiddled with that yet.
Windows fun
As an extra fun spot on Windows when using the MSVC compiler and libc… Cargo can find the host-native build tools for you, but gets really confused when you try to cross-build 32-bit on 64-bit sometimes.
And MSVC’s setup batch files are … hard to find reliably.
In the current batch file I’ve had some trouble getting the 32-bit build working, but 64-bit is ok. Yay!
Next steps
There’s a lot of little things left to do on mtpng: adding support for more chunks so it can handle indexed color images, color profiles, comments, etc… Ensuring the API is good and error handling is correct… Improving that build system. :)
And I think I can parallelize filtering and deflate better within a chunk, making compression faster for files too small for a single block. The same technique should work in reverse for decoding too.
Well, it’s been a fun project and I really think this is going to be useful as well as a great learning experience. :) Expect a couple more update posts in this series in the next couple weeks on those tuning issues, and fun little things I learn about Rust along the way!