When using ogv.js in the old IE 11 browser to play VP9 video, one of the biggest CPU hotspots is the vpx_convolve8_c function, which applies pixel filtering in a target area.
The C looks like:
 All the heavy lifting being in those two functions convolve_horiz and convolve_vert:
All the heavy lifting being in those two functions convolve_horiz and convolve_vert:


It looks a little oversimple with tight loops and function calls, but everything is inlined aggressively by the compiler and the inner loop unrolled. The asm.js looks something like:
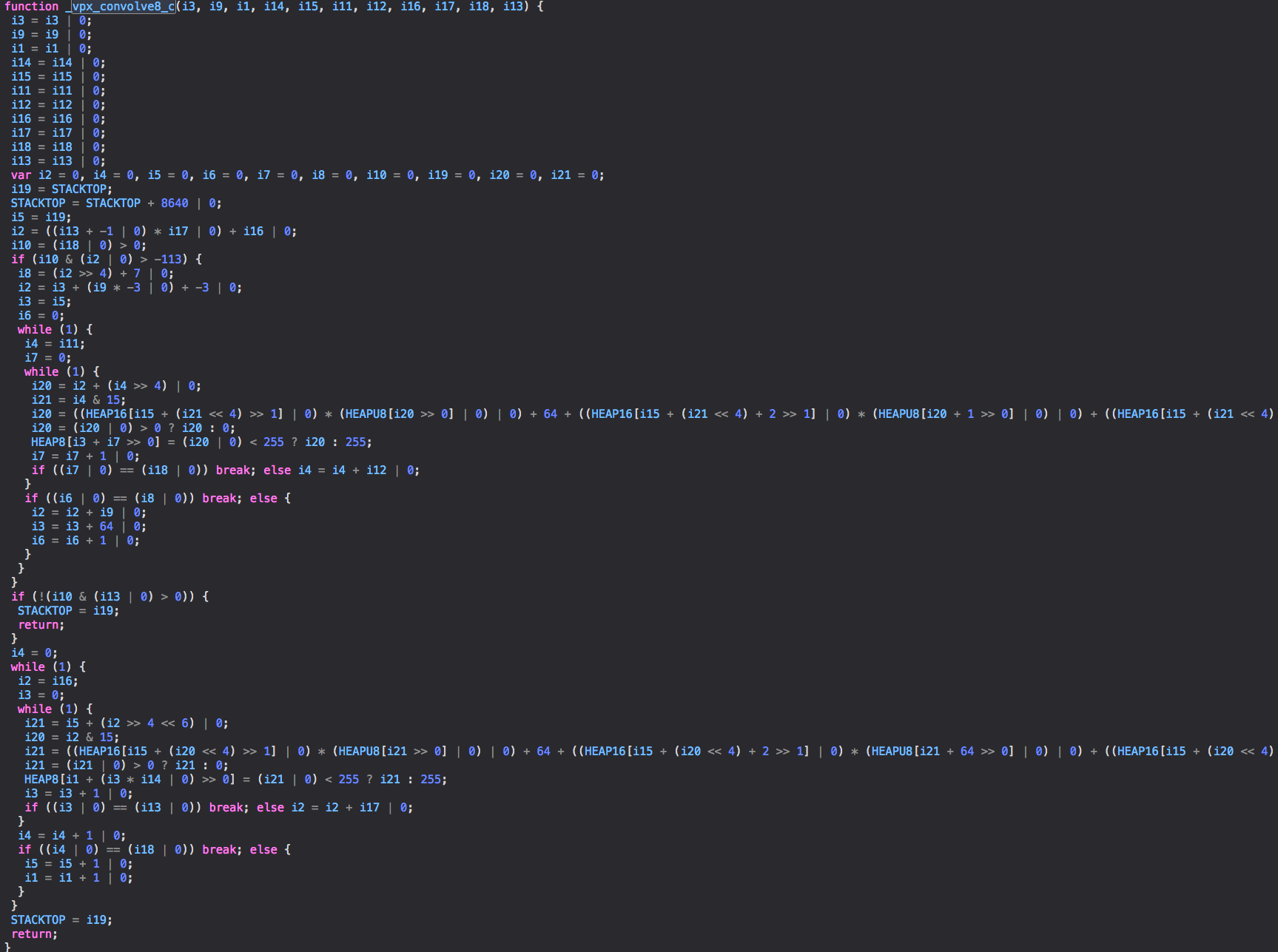
(Note some long lines are cut off in the unrolled loop.)
This seems fairly optimal, but know that those multiplications are slow — they’ll be floating-point multiplication because the semantics of JavaScript’s floating-point multiply operator don’t lend themselves well to automatic consolidation into integer multiplication. And it’s already an optimization that it’s doing _that_!
Normally emscripten actually doesn’t emit a multiply operator for an integer multiplication like this — it instead emits a call to Math.imul which implements 32-bit integer multiplication correctly and, when implemented, quickly. But in IE 11 there’s no native Math.imul instruction because it’s older than that addition to the JavaScript standard…
The emscripten compiler can provide an emulated replacement for Math.imul when using the LEGACY_VM_SUPPORT option, but it’s very slow — a function call, two multiplications, some bit-shifts, and addition.
Since I know (hope?) the multiplications inside libvpx never overflow, I run a post-processing pass on the JavaScript that replaces the very slow Math.imul calls with only moderately slow floating-point multiplications. This made a significant difference to total speed, something like 10-15%, when I added it to our VP8 and VP9 decoding.
Unfortunately optimizing it further looks tricky without SIMD optimizations. The native builds of these libraries make aggressive use of SIMD (single-instruction-multiple-data) to apply these filtering steps to several pixels at once, and it makes a huge improvement to throughput.
There has been experimentation for some time in SIMD support for asm.js, which seems to be being dropped now in favor of moving it directly into WebAssembly. If/when this eventually arrives in Safari it’ll be a big improvement there — but IE 11 will never update, being frozen in time.