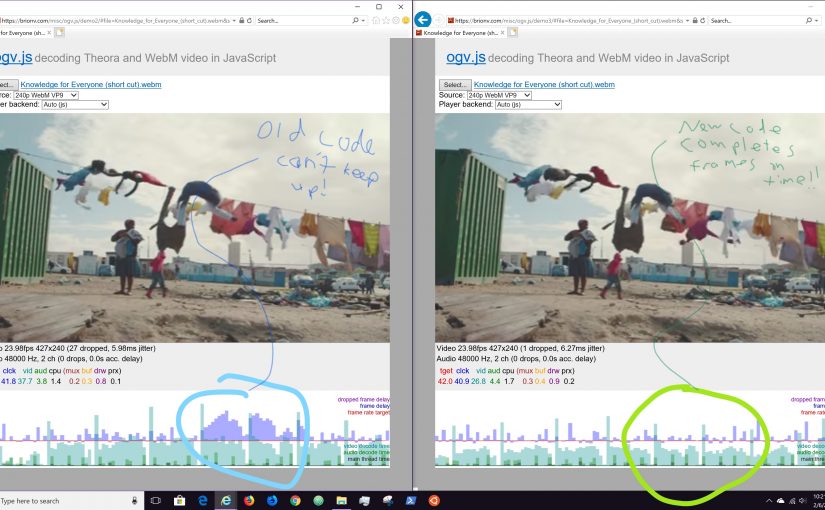
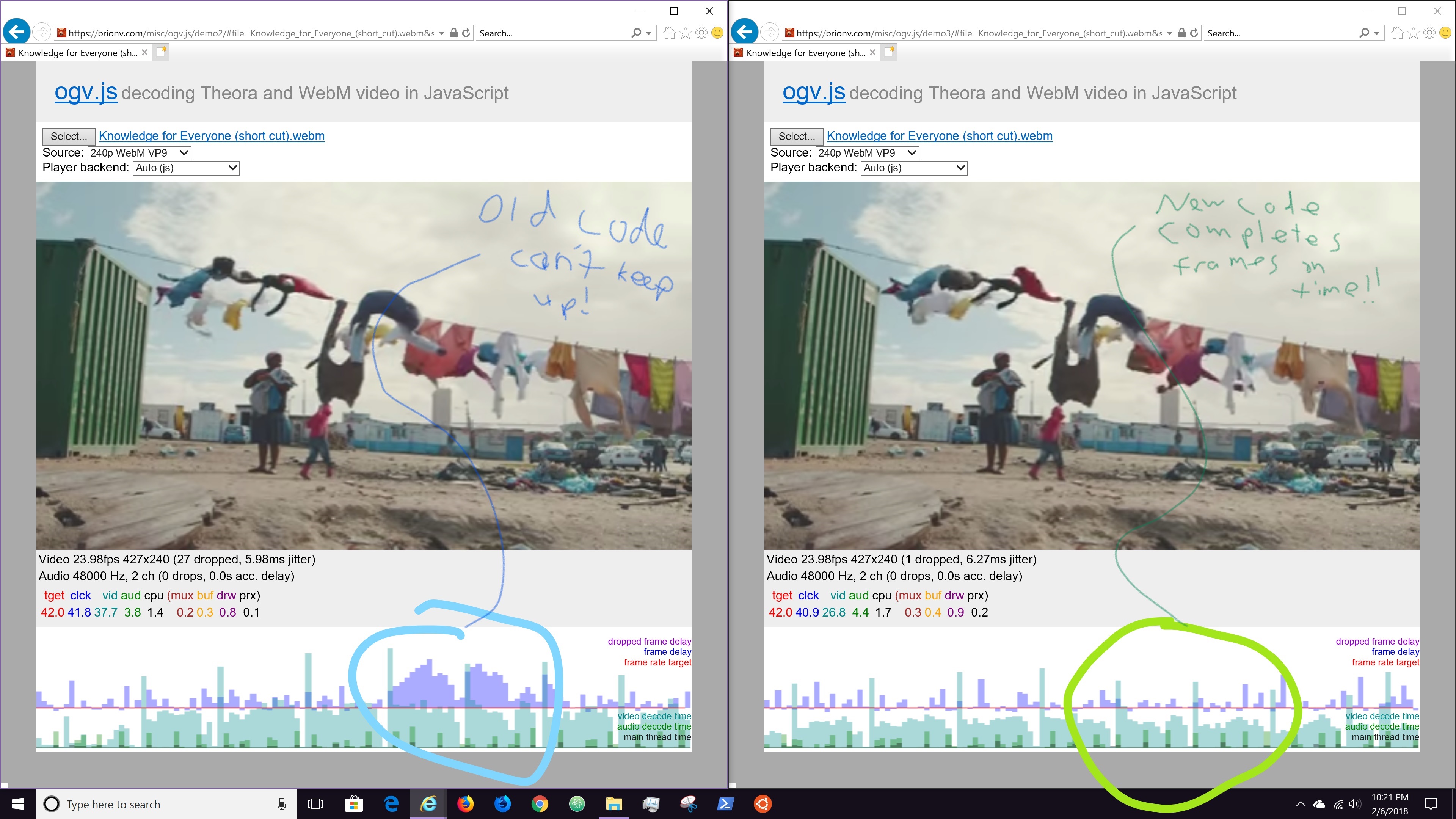
Another thing I’ve been researching is safe, sandboxed embedding of user-created JavaScript widgets… my last attempt in this direction was the EmbedScript extension (examples currently down, but code is still around).
User-level problems to solve:
- “Content”
- Diagrams, graphs, and maps would be more fun and educational if you could manipulate them more
- What if you could graph those equations on all those math & physics articles?
- Interactive programming sandboxes
- Customizations to editor & reading UI features
- Gadgets, site JS, shared user JS are potentially dangerous right now, requiring either admin review or review-it-yourself
- Narrower interfaces and APIs could allow for easier sharing of tools that don’t require full script access to the root UI
- Make scriptable extensions safer
- Use same techniques to isolate scripts used for existing video, graphs/maps, etc?
- Frame-based tool embedding + data injection could make export of rich interactive stuff as easy as InstantCommons…
Low-level problems to solve
- Isolating user-provided script from main web context
- Isolating user-provided script from outside world
- loading off-site resources is a security issue
- want to ensure that wiki resources are self-contained and won’t break if off-site dependencies change or are unavailable
- Providing a consistent execution environment
- browsers shift and change over time…
- Communicating between safe and sandboxed environments
- injecting parameters in safely?
- two-way comms for allowing privileged operations like navigating page?
- two-way comms for gadget/extension-like behavior?
- how to arrange things like fullscreen zoom?
- Potential offline issues
- offline cacheability in browser?
- how to use in Wikipedia mobile apps?
- Third-party site issues
- making our scripts usable on third-party wikis like InstantCommons
- making it easy for third-party wikis to use these techniques internally
Meta-level problems to solve
- How & how much to review code before letting it loose?
- What new problems do we create in misuse/abuse vectors?
Isolating user-provided scripts
One way to isolate user-provided scripts is to run them in an interpreter! This is potentially very slow, but allows for all kinds of extra tricks.
JS-Interpreter
I stumbled on JS-Interpreter, used sometimes with the Blockly project to step through code generated from visual blocks. JS-Interpreter implements a rough ES5 interpreter in native JS; it’s quite a bit slower than native (though some speedups are possible; the author and I have made some recent tweaks improving the interpreter loop) but is interesting because it allows single-stepping the interpreter, which opens up to a potential for an in-browser debugger. The project is under active development and could use a good regression test suite, if anyone wants to send some PRs. :)
The interpreter is also fairly small, weighing in around 24kb minified and gzipped.
The single-stepping interpreter design protects against infinite loops, as you can implement your own time limit around the step loop.
For pure-computation exercises and interactive prompts this might be really awesome, but the limited performance and lack of any built-in graphical display means it’s probably not great for hooking it up to an SVG to make it interactive. (Any APIs you add are your own responsibility, and security might be a concern for API design that does anything sensitive.)
Caja
An old project that’s still around is Google Caja, a heavyweight solution for embedding foreign HTML+JS using a server-side Java-based transpiler for the JS and JavaScript-side proxy objects that let you manipulate a subset of the DOM safely.
There are a number of security advisories in Caja’s history; some of them are transpiler failures which allow sandboxed code to directly access the raw DOM, others are failures in injected APIs that allow sandboxed code to directly access the raw DOM. Either way, it’s not something I’d want to inject directly into my main environment.
There’s no protection against loops or simple resource usage like exhausting memory.
Iframe isolation and CSP
I’ve looked at using cross-origin <iframe>s to isolate user code for some time, but was never quite happy with the results. Yes, the “same-origin policy” of HTML/JS means your code running in a cross-origin frame can’t touch your main site’s code or data, but that code is still able to load images, scripts, and other resources from other sites. That creates problems ranging from easy spamming to user information disclosure to simply breaking if required offsite resources change or disappear.
Content-Security-Policy to the rescue! Modern browsers can lock down things like network access using CSP directives on the iframe page.
CSP’s restrictions on loading resources still leaves an information disclosure in navigation — links or document.location can be used to navigate the frame to a URL on a third domain. This can be locked down with CSP’s childsrc param on the parent document — or an intermediate “double” iframe — to only allow the desired target domain (say, “*.wikipedia-embed.org” or even “item12345678.wikipedia-embed.org”). Then attempts to navigate the frame to a different domain from the inside are blocked.
So in principle we can have a rectangular region of the page with its own isolated HTML or SVG user interface, with its own isolated JavaScript running its own private DOM, with only the ability to access data and resources granted to it by being hosted on its private domain.
Further interactivity with the host page can be created by building on the postMessage API, including injecting additional resources or data sets. Note that postMessage is asynchronous, so you’re limited in simulating function calls to the host environment.
There is one big remaining security issue, which is that JS in an iframe can still block the UI for the whole page (or consume memory and other resources), either accidentally with an infinite loop or on purpose. The browser will eventually time out from a long loop and give you the chance to kill it, but it’s not pleasant (and might just be followed by another super-long loop!)
This means denial of service attacks against readers and editors are possible. “Autoplay” of unreviewed embedded widgets is still a bad idea for this reason.
Additionally, older browser versions don’t always support CSP — IE is a mess for instance. So defenses against cross-origin loads either need to somehow prevent loading in older browsers (poorer compatibility) or risk the information exposure (poorer security). However the most popular browsers do enforce it, so applications aren’t likely to be built that rely on off-site materials just to function, preventing which is one of our goals.
Worker isolation
There’s one more trick, just for fun, which is to run the isolated code in a Web Worker background thread. This would still allow resource consumption but would prevent infinite loops from blocking the parent page.
However you’re back to the interpreter’s problem of having no DOM or user interface, and must build a UI proxy of some kind.
Additionally, there are complications with running Workers in iframes, which is that if you apply sandbox=allow-scripts you may not be able to load JS into a Worker at all.
Non-JavaScript languages
Note that if you can run JavaScript, you can run just about anything thanks to emscripten. ;) A cross-compiled Lua interpreter weighs in around 150-180kb gzipped (depending on library inclusion).
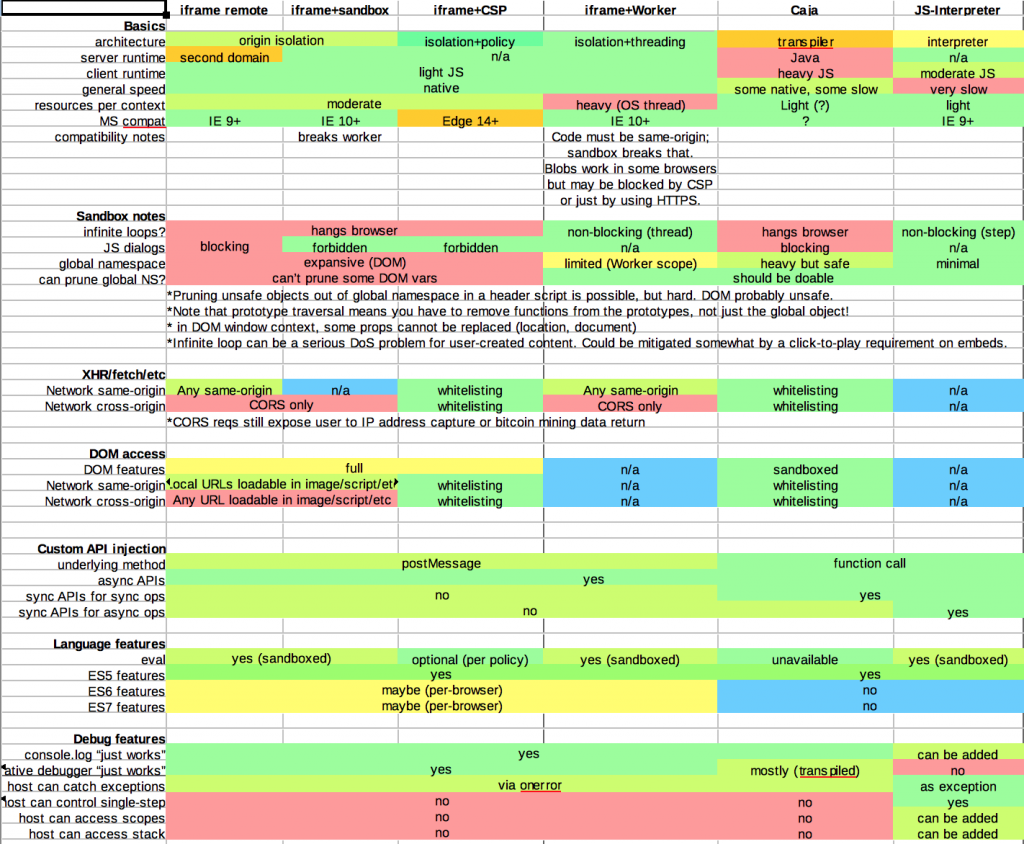
Big chart
Here, have a big chart I made for reference:
Offline considerations
In principle the embedding sites can be offline-cached… bears consideration.
App considerations
The iframes could be loaded in a webview in apps, though consider the offline + app issues!
Data model
A widget (or whatever you call it) would have one or more sub resources, like a Gadget does today plus more:
- HTML or SVG backing document
- JS/CSS module(s), probably with a dependency-loading system
- possibly registration for images and other resources?
- depending on implementation it may be necessary to inject images as blobs or some weird thing
- for non-content stuff, some kind of registry for menu/tab setup, trigger events, etc
Widgets likely should be instantiable with input parameters like templates and Lua modules are; this would be useful for things like reusing common code with different input data, like showing a physics demo with different constant values.
There should be a human-manageable UI for editing and testing these things. :) See jsfiddle etc for prior art.
How to build the iframe target site
Possibilities:
- Subdomain per instance
- actually serve out the target resources on a second domain, each ‘widget instance’ living in a separate random subdomain ideally for best isolation
- base HTML or SVG can load even if no JS. Is that good or bad, if interactivity was the goal?
- If browser has no CSP support, the base HTML/CSS/JS might violate constraints.
- can right-click and open frame in new window
- …but now you have another out of context view of data, with new URLs. Consider legal, copyright, fairuse, blah blah
- have to maintain and run that second domain and hook it up to your main wiki
- how to deal with per-instance data input? Pre-publish? postMessage just that in?
- injecting data over postMessage maybe best for the InstantCommons-style scenario, since sites can use our scripts but inject data
- probably easier debugging based on URLs
- Subdomain per service provider, inject resources and instance data
- Inject all HTML/SVG/JS/CSS at runtime via postMessage (trusting the parent site origin). Images/media could either be injected as blobs or whitelisted by URL.
- The service provider could potentially be just a static HTML file served with certain strict CSP headers.
- If injecting all resources, then could use a common provider for third-party wikis.
- third-party wikis could host their own scripts using this technique using our frame broker. not sure if this is good idea or not!
- No separate content files to host, nothing to take down in case of legal issues.
- Downside: right-clicking a frame to open it in new window won’t give useful resources. Possible workarounds with providing a link-back in a location hash.
- Script can check against a user-agent blacklist before offering to load stuff.
- Downside: CSP header may need to be ‘loose’ to allow script injection, so could open you back up to XSS on parameters. But you’re not able to access outside the frame so pssssh!
Abuse and evil possibilities
Even with the security guarantees of origin restrictions and CSP, there are new and exciting threat models…
Simple denial of service is easy — looping scripts in an iframe can lock up the main UI thread for the tab (or whole browser, depending on the browser) until it eventually times out with an error. At which point it can potentially go right back into a loop. Or you can allocate tons of memory, slowing down and eventually perhaps crashing the browser. Even tiny programs can have huge performance impact, and it’s hard to predict what will be problematic. Thus script on a page could make it hard for other editors and admins to get back in to fix the page… For this reason I would recommend against autoplay in Wikipedia articles of arbitrary unreviewed code.
There’s also possible trolling patterns: hide a shock image in a data set or inside a seemingly safe image file, then display it in a scriptable widget bypassing existing image review.
Advanced widgets could do all kinds of fun and educational things like run emulators for old computer and game systems. That brings with it the potential for copyright issues with the software being run, or for newer systems patent issues with the system being emulated.
For that matter you could run programs that are covered under software patents, such as decoding or encoding certain video file formats. I guess you could try that in Lua modules too, but JS would allow you to play or save result files to disk directly from the browser.
WP:BEANS may apply to further thoughts on this road, beware. ;)
Ideas from Jupyter: frontend/backend separation
Going back to Jupyter/IPython as an inspiration source; Jupyter has a separation between a frontend that takes interactive input and displays output, and a backend kernel which runs the actual computation server-side. To make for fancier interactive displays, the output can have a widget which runs some sort of JavaScript component in the frontend notebook page’s environment, and can interact with the user (via HTML controls), with other widgets (via declared linkages) and with the kernel code (via events).
We could use a model like this which distinguishes between trusted (or semi-trusted) frontend widget code which can do anything it can do in its iframe, but must be either pre-reviewed, or opted into. Frontend widgets that pass review should have well-understood behavior, good documentation, stable interfaces for injecting data, etc.
The frontend widget can and should still be origin-isolated & CSP-restricted for policy enforcement even if code is reviewed — defense in depth is important!
Such widgets could either be invoked from a template or lua module with a fixed data set, or could be connected to untrusted backend code running in an even more restricted sandbox.
The two main ‘more restricted sandbox’ possibilities are to run an interpreter that handles loops safely and applies resource limits, or to run in a worker thread that doesn’t block the main UI and can be terminated after a timeout…. but even that may be able to exhaust system resources via memory allocation.
I think it would be very interesting to extend Jupyter in two specific ways:
- iframe-sandboxing the widget implementations to make loading foreign-defined widgets safer
- implementing a client-side kernel that runs JS or Lua code in an interpreter, or JS in a sandboxed Worker, instead of maintaining a server connection to a Python/etc kernel
It might actually be interesting to adopt, or at least learn from, the communication & linkage model for the Jupyter widgets (which is backbone.js-based, I believe) and consider the possibilities for declarative linkage of widgets to create controllable diagrams/visualizations from common parts.
An interpreter-based Jupyter/IPython kernel that works with the notebooks model could be interesting for code examples on Wikipedia, Wikibooks etc. Math potential as well.
Short-term takeaways
- Interpreters look useful in niche areas, but native JS in iframe+CSP probably main target for interactive things.
- “Content widgets” imply new abuse vectors & thus review mechanisms. Consider short-term concentration on other areas of use:
- sandboxing big JS libraries already used in things like Maps/Graphs/TimedMediaHandler that have to handle user-provided input
- opt-in Gadget/user-script tools that can adapt to a “plugin”-like model
- making those things invocable cross-wiki, including to third-party sites
- Start a conversation about content widgets.
- Consider starting with strict-review-required.
- Get someone to make the next generation ‘Graphs’ or whatever cool tool as one of these instead of a raw MW extension…?
- …slowly plan world domination.