At Wikipedia we have long articles containing many images, some of which need a lot of detail and others which will be scrolled past or missed entirely. We’re looking into lazy-loading, alternate formats such as WebP, and other ways to balance display density vs network speed.
I noticed that VP9 supports scaling of reference frames from different resolutions, so a frame that changes video resolution doesn’t have to be a key frame.
This means that a VP9-based still image format (unlike VP8-based WebP) could encode multiple resolutions to be loaded and decoded progressively, at each step encoding only the differences from the previous resolution level.
So to load an image at 2x “Retina” display density, we’d load up a series of smaller, lower density frames, decoding and updating the display until reaching the full size (say, 640×360). If the user scrolls away before we reach 2x, we can simply stop loading — and if they scroll back, we can pick up right where we left off.
I tried hacking up vpxenc to accept a stream of concatenated PNG images as input, and it seems plausible…
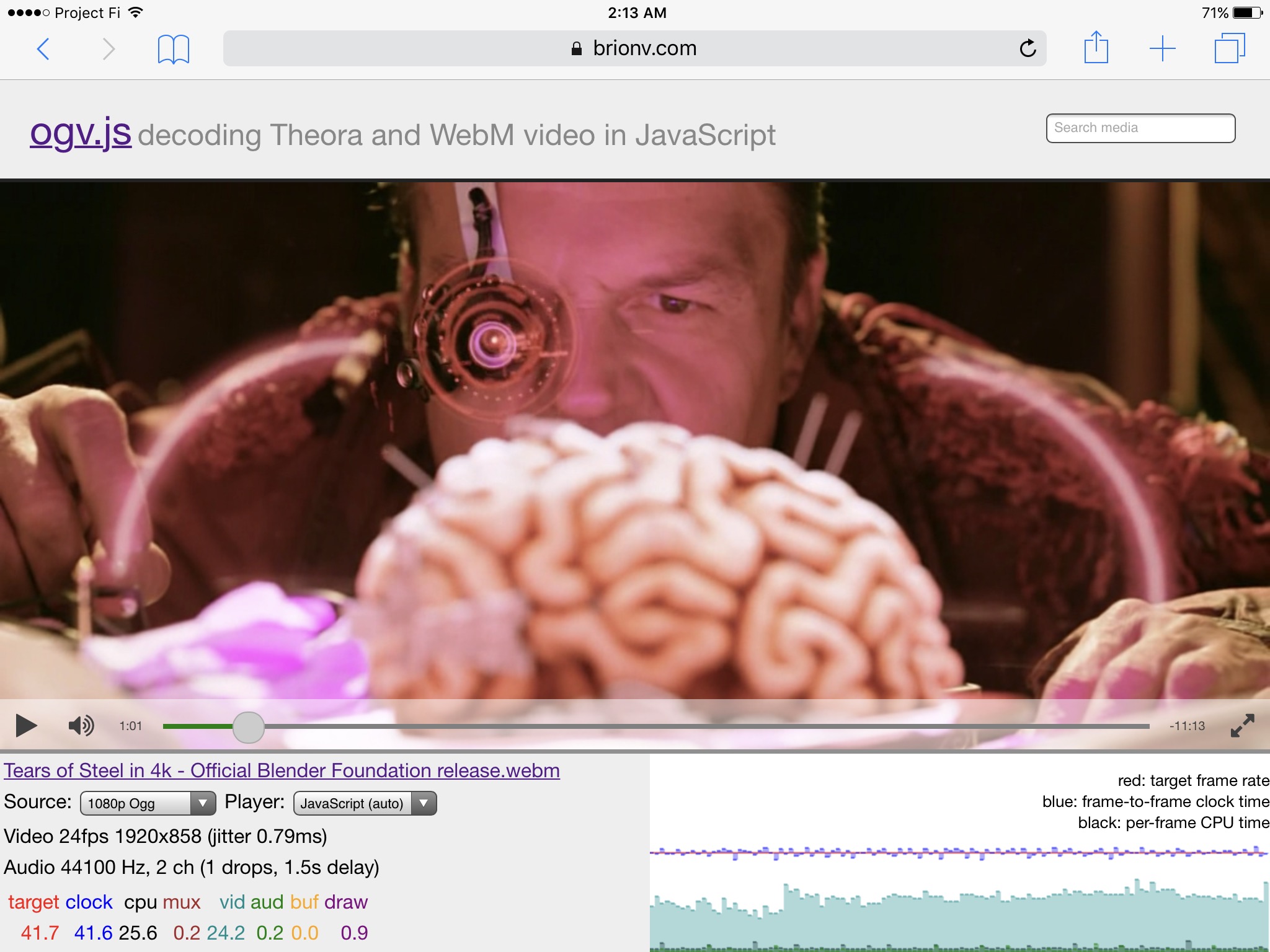
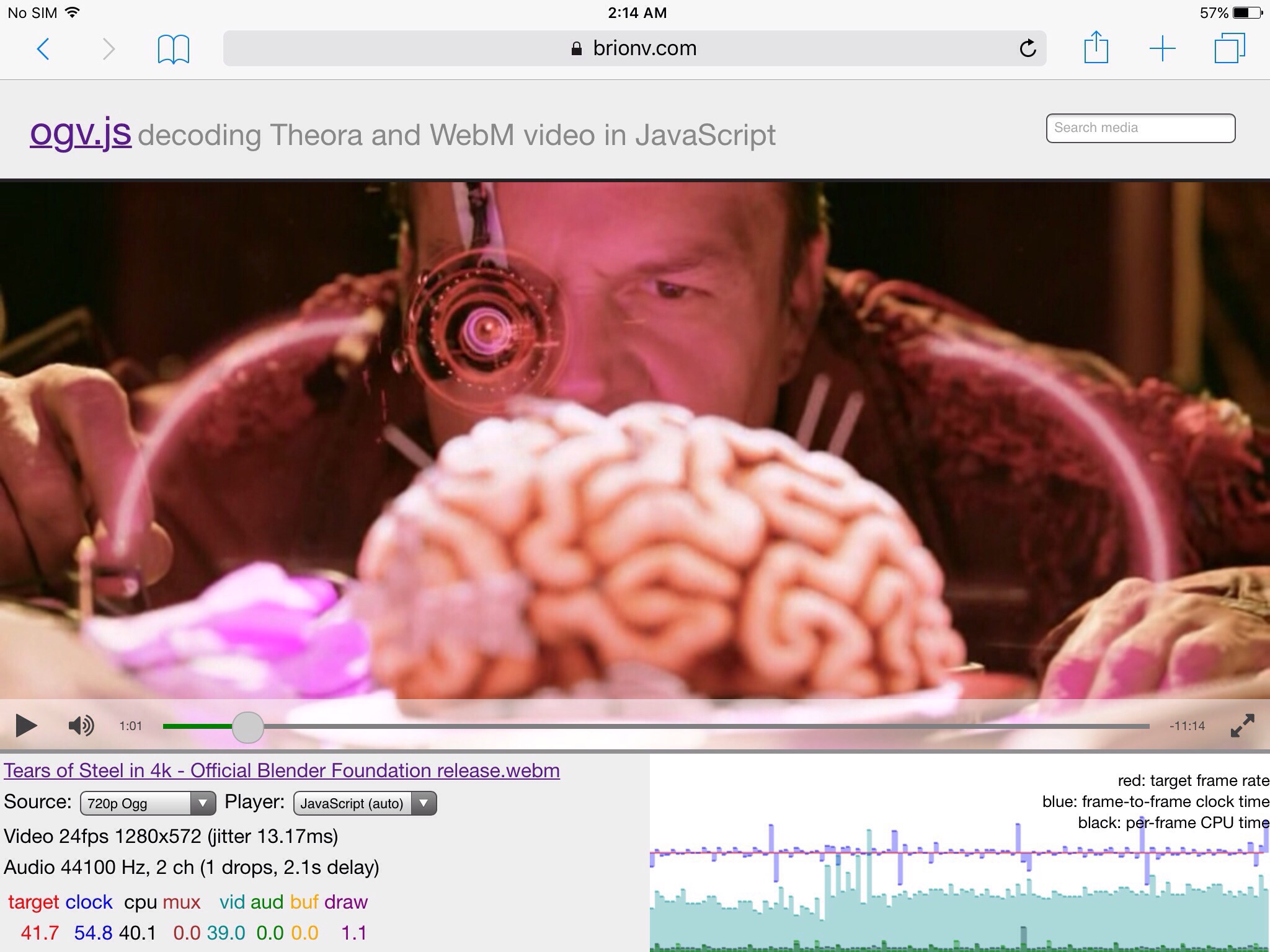
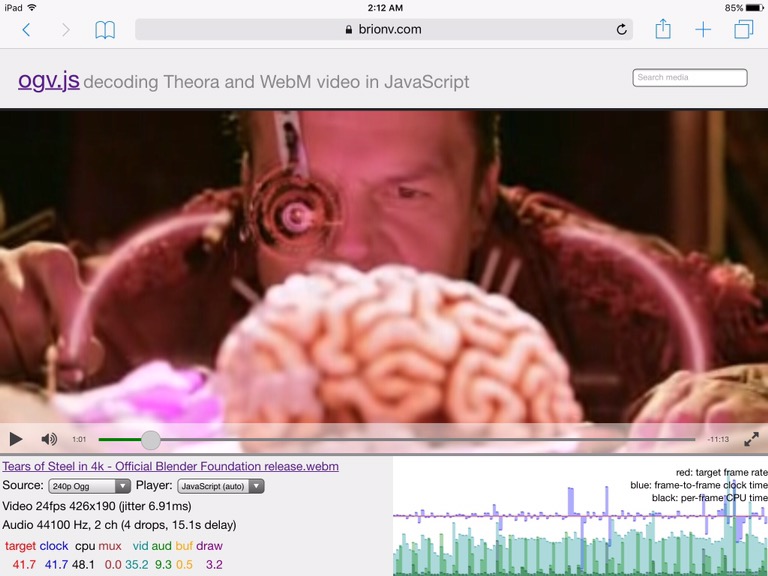
Demo page with a few sample images (not yet optimized for network load; requires Firefox or Chrome):
https://media-streaming.wmflabs.org/pic9/
Compared to loading a series of intra-coded JPEG or WebP images, the total data payload to reach resolution X is significantly smaller. Compared against only loading the final resolution in WebP or JPEG, without any attempt at tuning I found my total payloads with VP9 to be about halfway between the two formats, and with tuning I can probably beat WebP.
Currently the demo loads the entire .webm file containing frames up to 4x resolution, seeking to the frame with the target density. Eventually I’ll try repacking the frames into separately loadable files which can be fed into Media Source Extensions or decoded via JavaScript… That should prevent buffering of unused high resolution frames.
Some issues:
Changing resolutions always forces a keyframe unless doing single-pass encoding with frame lag set to 1. This is not super obvious, but is neatly enforced in encoder_set_config in vp9_cx_iface.h! Use –passes=1 –lag-in-frames=1 options to vpxenc.
Keyframes are also forced if width/height go above the “initial” width/height, so I had to start the encode with a stub frame of the largest size (solid color, so still compact). I’m a bit unclear on whether there’s any other way to force the ‘initial’ frame size to be larger, or if I just have to encode one frame at the large size…
There’s also a validity check on resized frames that forces a keyframe if the new frame is twice or more the size of the reference frame. I used smaller than 2x steps to work around this (tested with steps at 1/8, 1/6, 1/4, 1/2, 2/3, 1, 3/2, 2, 3, 4x of the base resolution).
I had to force updates of the golden & altref on every frame to make sure every frame ref’d against the previous, or the decoder would reject the output. –min-gf-interval=1 isn’t enough; I hacked vpxenc to set the flags on the frame encode to VP8_EFLAG_FORCE_GF | VP8_EFLAG_FORCE_ARF.
I’m having trouble loading the VP9 webm files in Chrome on Android; I’m not sure if this is because I’m doing something too “extreme” for the decoder on my Nexus 5x or if something else is wrong…