Every once in a while we get a rash of complaints about how Wikipedia renders on somebody’s mobile phone or PDA web browser.
Unfortunately we don’t seem to have a lot of such devices ourselves to test with, and they all behave differently, so we haven’t really had the resources to seriously work on testing tweaks for better phone/handheld support.
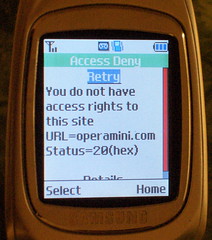
My crappy little phone just has some kind of WAP browser, I think, which I’ve never really been able to get to do anything productive. For kicks I took a peek to see if Opera Mini would run on my phone, since I *think* it has some kind of Java… alas, once I finally got connected to the site it claimed my phone isn’t supported.
Opera Mini actually handles Wikipedia pretty decently. The really cool thing is that since the client side is Java, they have an applet version so you can test the actual Opera Mini rendering in any desktop web browser. I LOVE YOU OPERA! YOU MAKE IT POSSIBLE TO TEST MY WEB SITE IN YOUR PRODUCT!!!! IIII LLLLLOOOOVVEEE YYOOOUUUUU!!!!!!!ONE
Of course currently our fundraising drive notice covers the entire screen, but… hey… ;)
Update 2007-01-07: I’m collecting links to mobile testing resources at [[mw:Mobile browser testing]].

{kind=link}