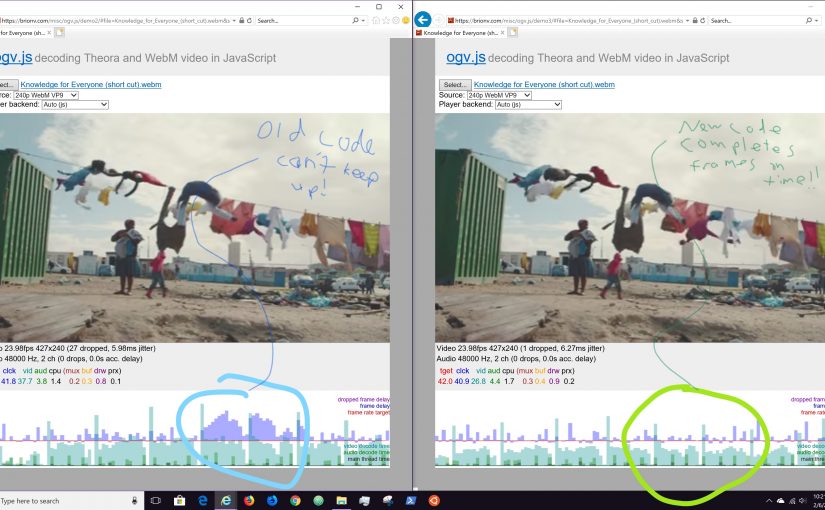
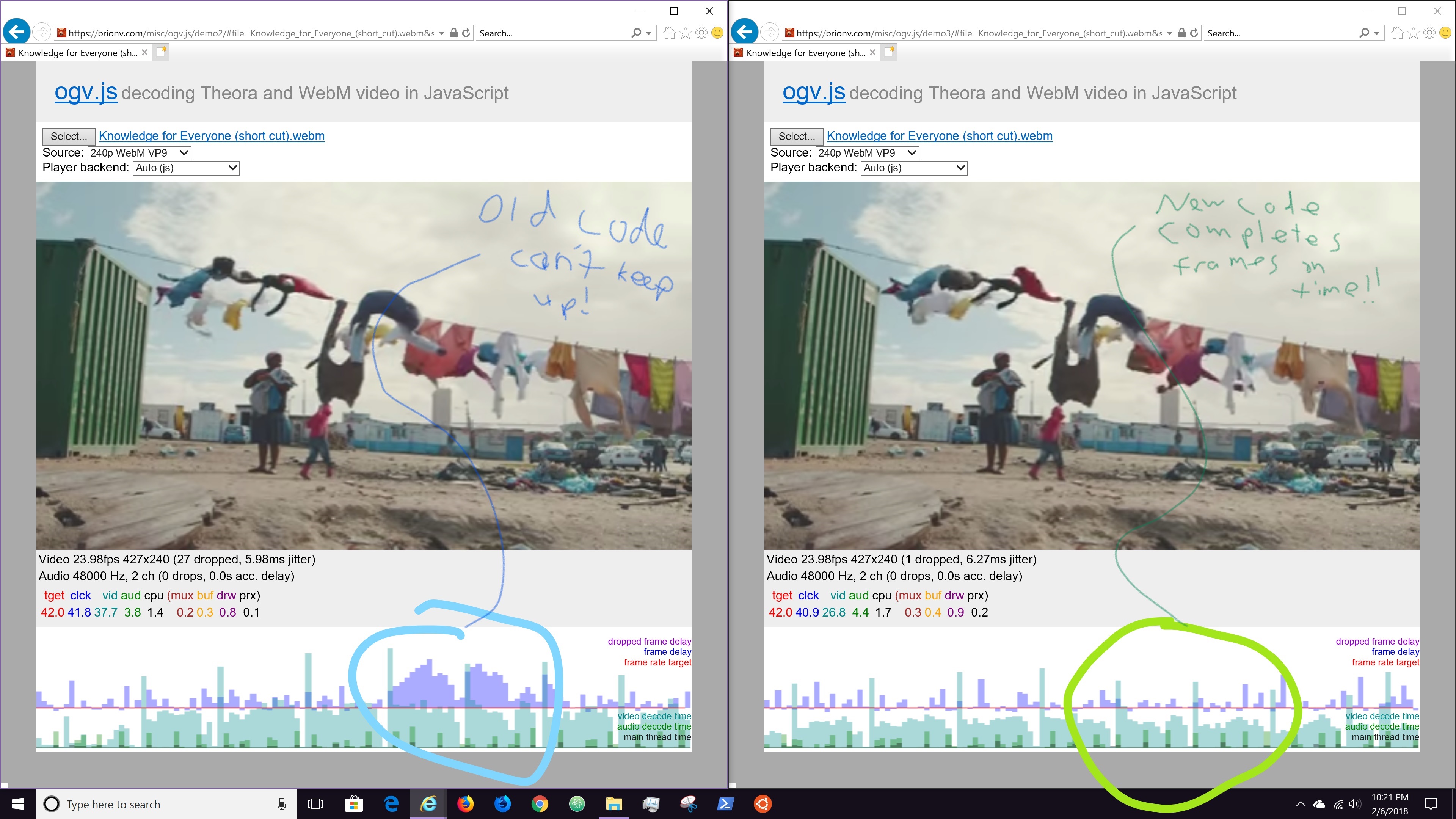
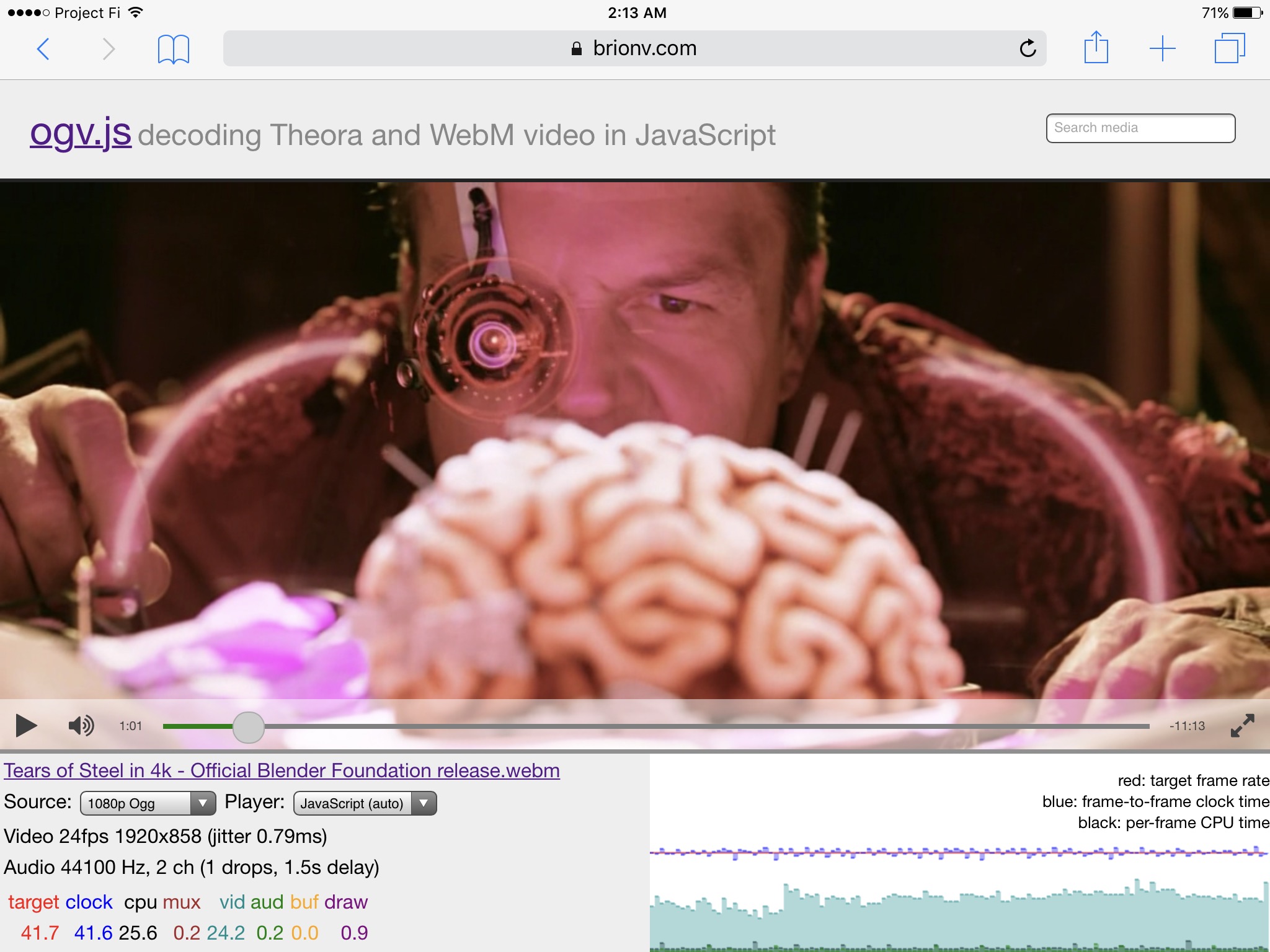
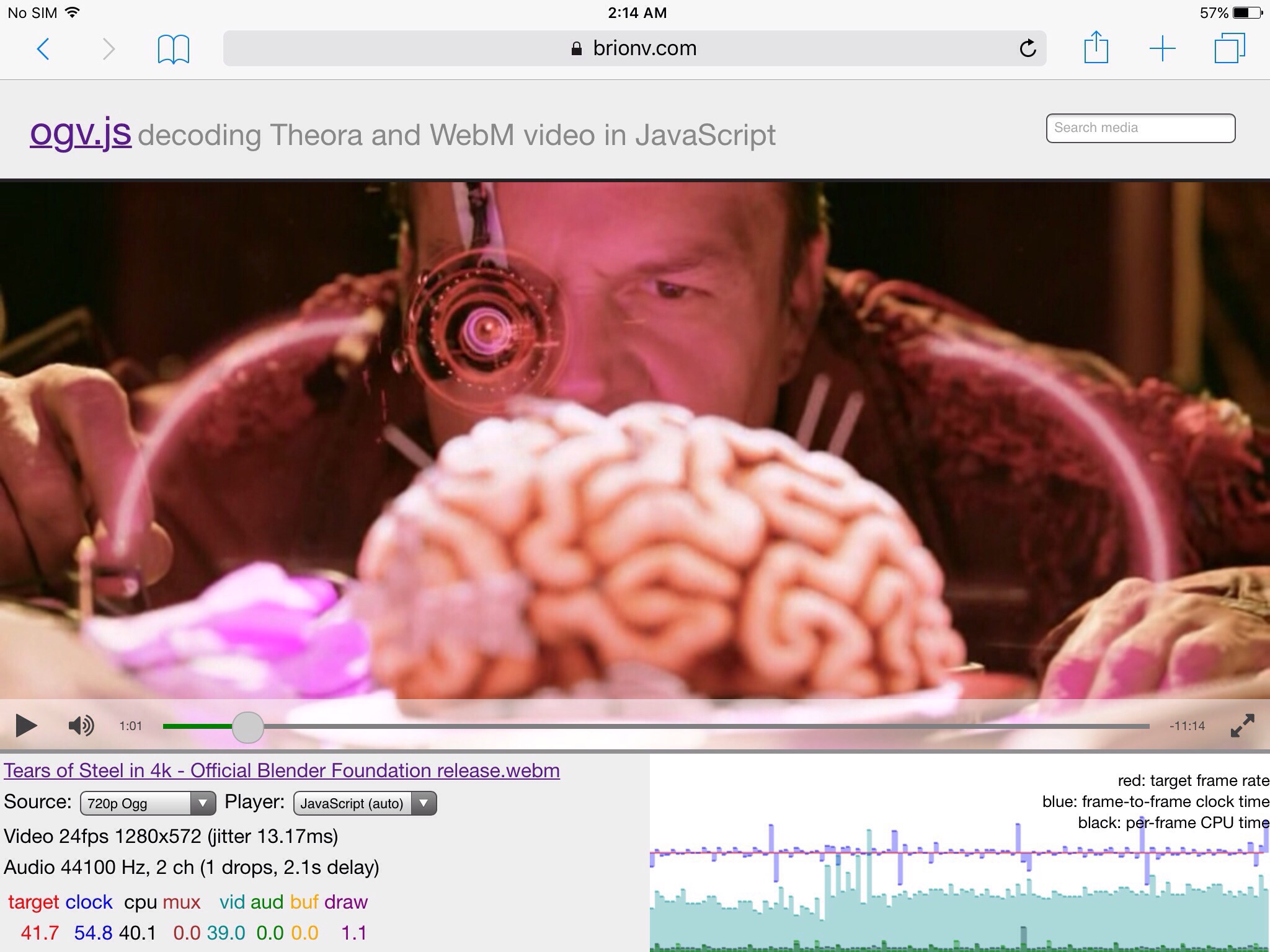
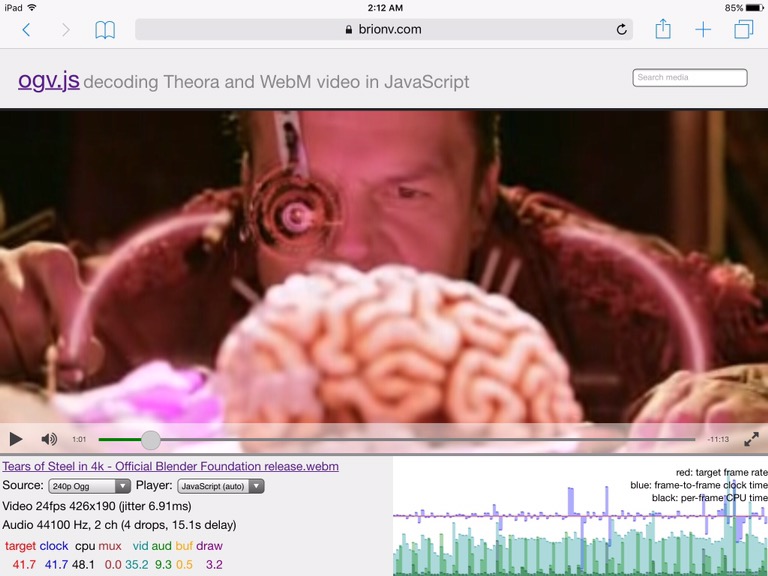
I’ve taken a break from the blog for too long! Time to update some on current work. We’re doing a final push on the video.js-based frontend media player for MediaWiki’s TimedMediaHandler, with some new user interface bits, better mobile support, and laying the foundation for smoother streaming in the future.
Among other things, I’m doing some cleanup on the AudioFeeder component in the ogv.js codec shim, which is still used in Safari on iOS devices and older Macs.
This abstracts a digital sound output channel with an append-only buffer, which can be stopped/started, the volume changed, and the current playback position queried.
When I was starting on this work in 2014 or so, Internet Explorer 11 was supported so I needed a Flash backend for IE, and a Web Audio backend for Safari… at the time, the only way to create the endless virtual buffer in Web Audio was using a ScriptProcessorNode, which ran its data-manipulation callback on the main thread. This required a fairly large buffer size for each callback to ensure the browser’s audio thread had data available if the main thread was hung up on drawing a video frame or something.
Fast forward to 2022: IE 11 and Flash are EOL and I’ve been able to drop them from our support matrix. Safari and other browsers still support ScriptProcessorNode, but it’s been officially deprecated for a while in favor of AudioWorklets.
I’ve been meaning to look into upgrading with an AudioWorklet backend but hadn’t had need; however I’m seeing some performance problems with the current code on Safari Technology Preview, especially on my slower 2015 MacBook Pro which doesn’t grok VP9 in hardware so needs the shim. :) Figured it’s worth taking a day or two to see if I can avoid a perf regression on old Macs when the next Safari update comes out.
So first — what’s a worklet? This is an interface that’s being adopted by a few web bits (I think some CSS animation bits are using these too) to have a fairly structured way of loading little scripts into a dedicated worker thread (the worklet) to do specific things off-main-thread that are performance critical (audio, layout, animation).
An AudioWorkletNode hooks into the Web Audio graph, giving something similar to a ScriptProcessorNode but where the processing callback runs in the worklet, on an AudioWorkletProcessor subclass. The processor object has audio-specific stuff like the media time at the start of the buffer, and is given input/output channels to read/write.
For an ever-growing output, we use 0 inputs and 1 output; ideally I can support multichannel audio as well, which I never bothered to do in the old code (for simplicity it downmixed everything to stereo). Because the worklet processors run on a dedicated thread, the data comes in small chunks — by default something like 128 samples — whereas I’d been using like 8192-sample buffers on the main thread! This allows you to have low latency, if you prefer it over a comfy buffer.
Communicating with worker threads traditionally sucks in JavaScript — unless you opt into the new secure stuff for shared memory buffers you have to send asynchronous messages; however those messages can include structured data so it’s easy to send Float32Arrays full of samples around.
The AudioWorkletNode on the main thread gets its own MessagePort, which connects to a fellow MessagePort on the AudioWorkletProcessor in the audio thread, and you can post JS objects back and forth, using the standard “structured clone” algorithm for stripping out local state.
I haven’t quite got it running yet but I think I’m close. ;) On node creation, an initial set of queued buffers are sent in with the setup parameters. When audio starts playing, after the first callback copies out its data it posts some state info back to the main thread, with the audio chunk’s timestamp and the number of samples output so far.
The main thread’s AudioFeeder abstraction can then pair those up to report what timestamp within the data feed is being played now, with compensation for any surprises (like the audio thread missing a callback itself, or a buffer underrun from the main thread causing a delay).
When stopping, instead of just removing the node from the audio graph, I’ve got the main thread sending down a message that notifies the worklet code that it can safely stop, and asking for any remaining data back. This is important if we’ve maintained a healthy buffer of decoded audio; in case we continue playback from the same position, we can pass the buffers back into the new worklet node.
I kinda like the interface now that I’m digging in it. Should work… Either tonight or tomorrow hope to sort that out and get ogv.js updated in-tree again in TMH.