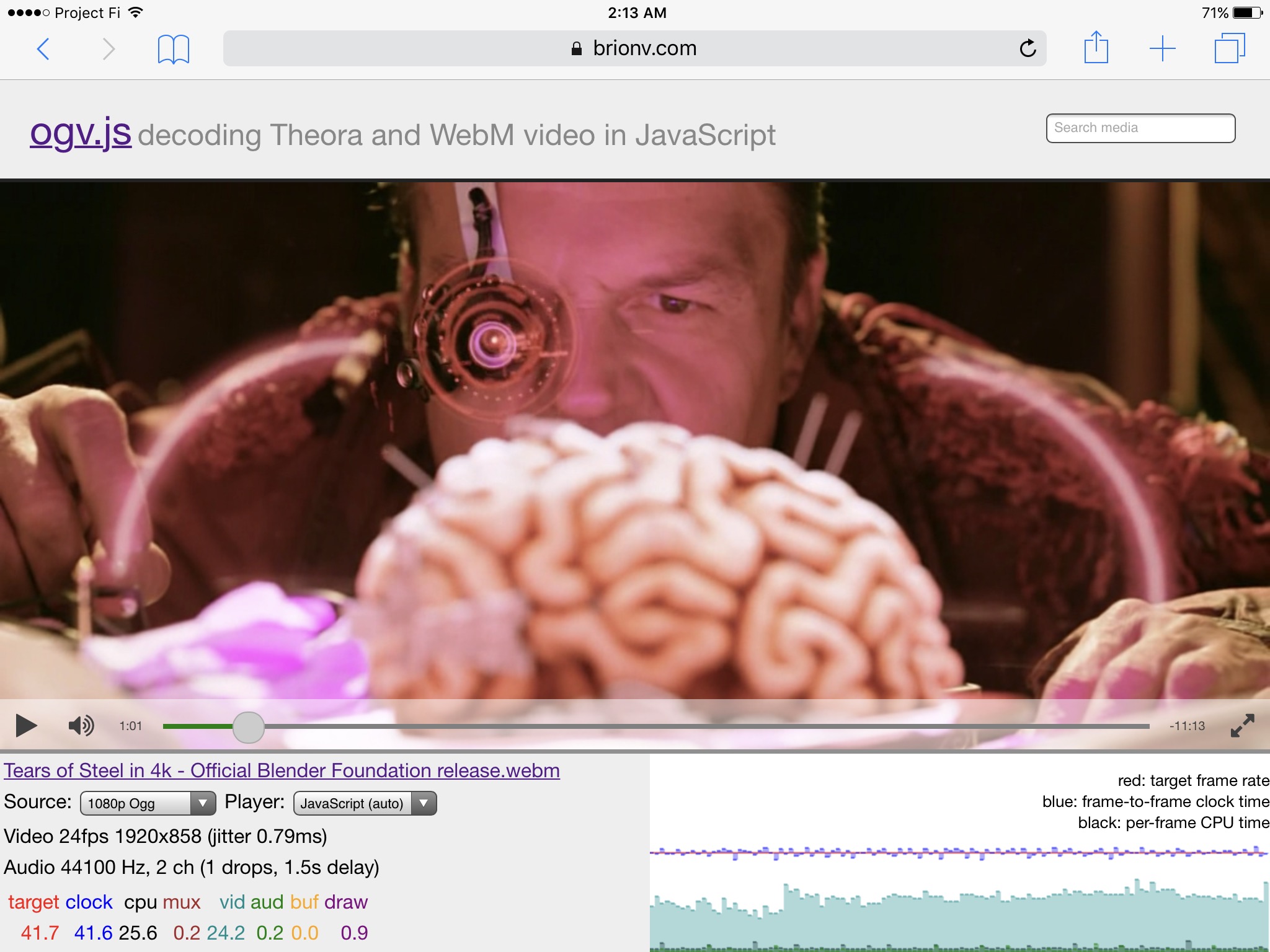
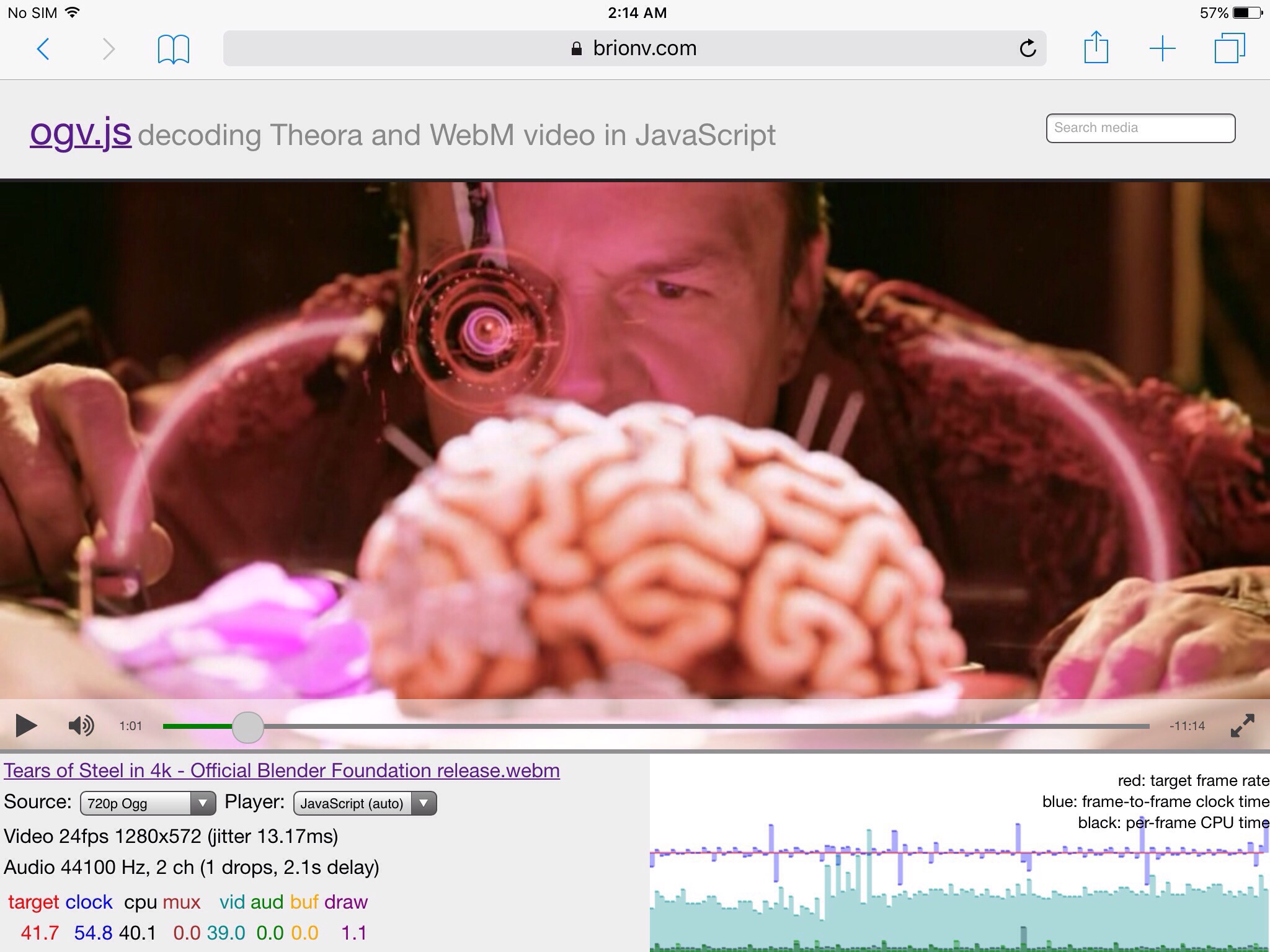
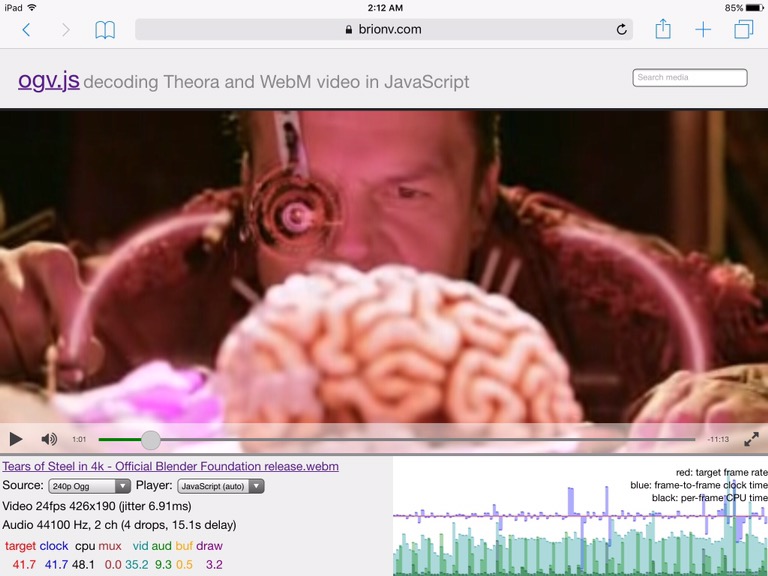
In my last post I described using AVSampleBufferDisplayLayer to output manually-uncompressed YUV video frames in an iOS app, for playing WebM and Ogg files from Wikimedia Commons. After further experimentation I’ve decided to instead stick with using OpenGL ES directly, and here’s why…
- 640×360 output regularly displays with a weird horizontal offset corruption on iPad Pro 9.7″. Bug filed as rdar://29810344
- Can’t get any pixel format with 4:4:4 subsampling to display. Theora and VP9 both support 4:4:4 subsampling, so that made some files unplayable.
- Core Video pixel buffers for 4:2:2 and 4:4:4 are packed formats, and it prefers 4:2:0 to be a weird biplanar semi-packed format. This requires conversion from the planar output I already have, which may be cheap with Neon instructions but isn’t free.
Instead, I’m treating each plane as a separate one-channel grayscale image, which works for any chroma subsampling ratios. I’m using some Core Video bits (CVPixelBufferPool and CVOpenGLESTextureCache) to do texture setup instead of manually calling glTeximage2d with a raw source blob, which improves a few things:
- Can do CPU->GPU memory copy off main thread easily, without worrying about locking my GL context.
- No pixel format conversions, so straight memcpy for each line…
- Buffer pools are tied to the video buffer’s format object, and get swapped out automatically when the format changes (new file, or file changes resolution).
- Don’t have to manually account for stride != width in the texture setup!
It could be more efficient still if I could pre-allocate CVPixelBuffers with on-GPU memory and hand them to libvpx and libtheora to decode into… but they currently lack sufficient interfaces to accept frame buffers with GPU-allocated sizes.
A few other oddities I noticed:
- The clean aperture rectangle setting doesn’t seem to be preserved when creating a CVPixelBuffer via CVPixelBufferPool; I have to re-set it when creating new buffers.
- For grayscale buffers, the clean aperture doesn’t seem to be picked up by CVOpenGLESTextureGetCleanTexCoords. Not sure if this is only supposed to work with Y’CbCr buffer types or what… however I already have all these numbers in my format object and just pull from there. :)
I also fell down a rabbit hole researching color space issues after noticing that some of the video formats support multiple colorspace variants that may imply different RGB conversion matrices… and maybe gamma…. and what do R, G, and B mean anyway? :) Deserves another post sometime.